
Introduction#
Using search systems in conjunction with a large language model (LLM) is a common paradigm for enabling language models to access data beyond their training corpus. This approach, broadly known as retrieval-augmented-generation (RAG), has traditionally relied on single-stage retrieval pipelines composed of vector search, lexical search, or regular expression matching, optionally followed by a learned reranker. While effective for straightforward lookup queries, these pipelines are fundamentally limited: they assume that the information needed to answer a question can be retrieved in a single pass.
In practice, many real-world queries are not satisfiable in a single-stage. Answering a question often requires a chain of intermediate searches in which the output of one search informs the next, a process known as a multi-hop retrieval.
To solve this, leveraging LLMs for multi-turn agentic search has become a viable approach to answering multi-hop retrieval queries. Rather than issuing a single query, an LLM agent iteratively decomposes a high-level question into subqueries, retrieves evidence, and refines its search strategy across multiple turns. Concurrently, it has been shown that smaller-parameter language models, trained on moderate-scale corpora, can serve as effective search agents with performance comparable to substantially larger models. Running frontier-scale models for multi-turn search incurs high cost and latency, which motivates offloading this task to a smaller, purpose-trained model.
A key factor driving the cost and latency of agentic search is the growth of the context window. As the agent gathers information over multiple turns, its context window fills rapidly with retrieved documents, many of which may be tangential or redundant. This bloated context not only increases computational cost but can also degrade downstream performance due to increasing the presence of distracting information. One promising direction to address this is self-editing context, in which the agent actively decides which retrieved information to retain and which to discard, allowing it to continue long-horizon search tasks more efficiently and more accurately within a bounded context window.
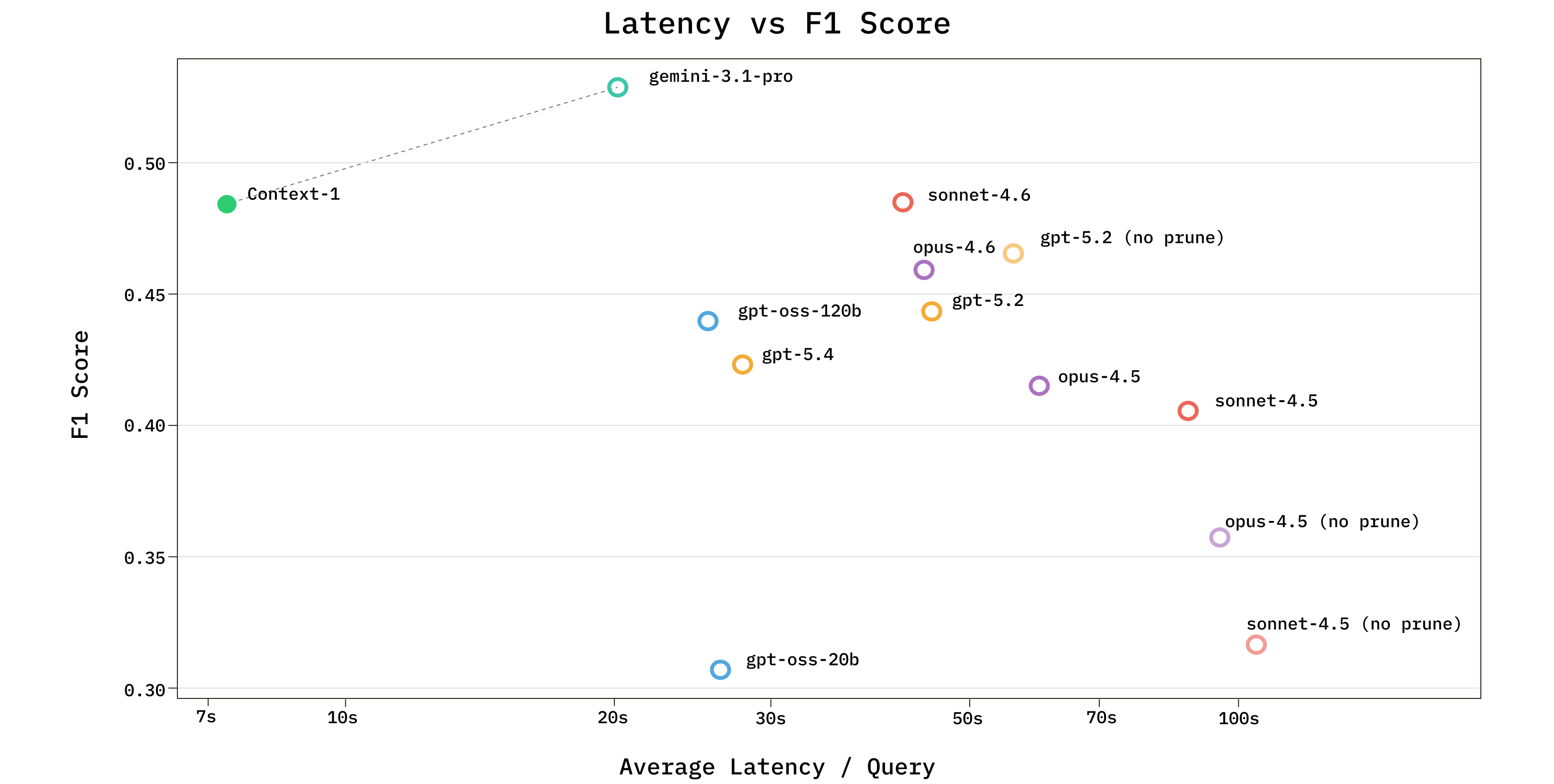
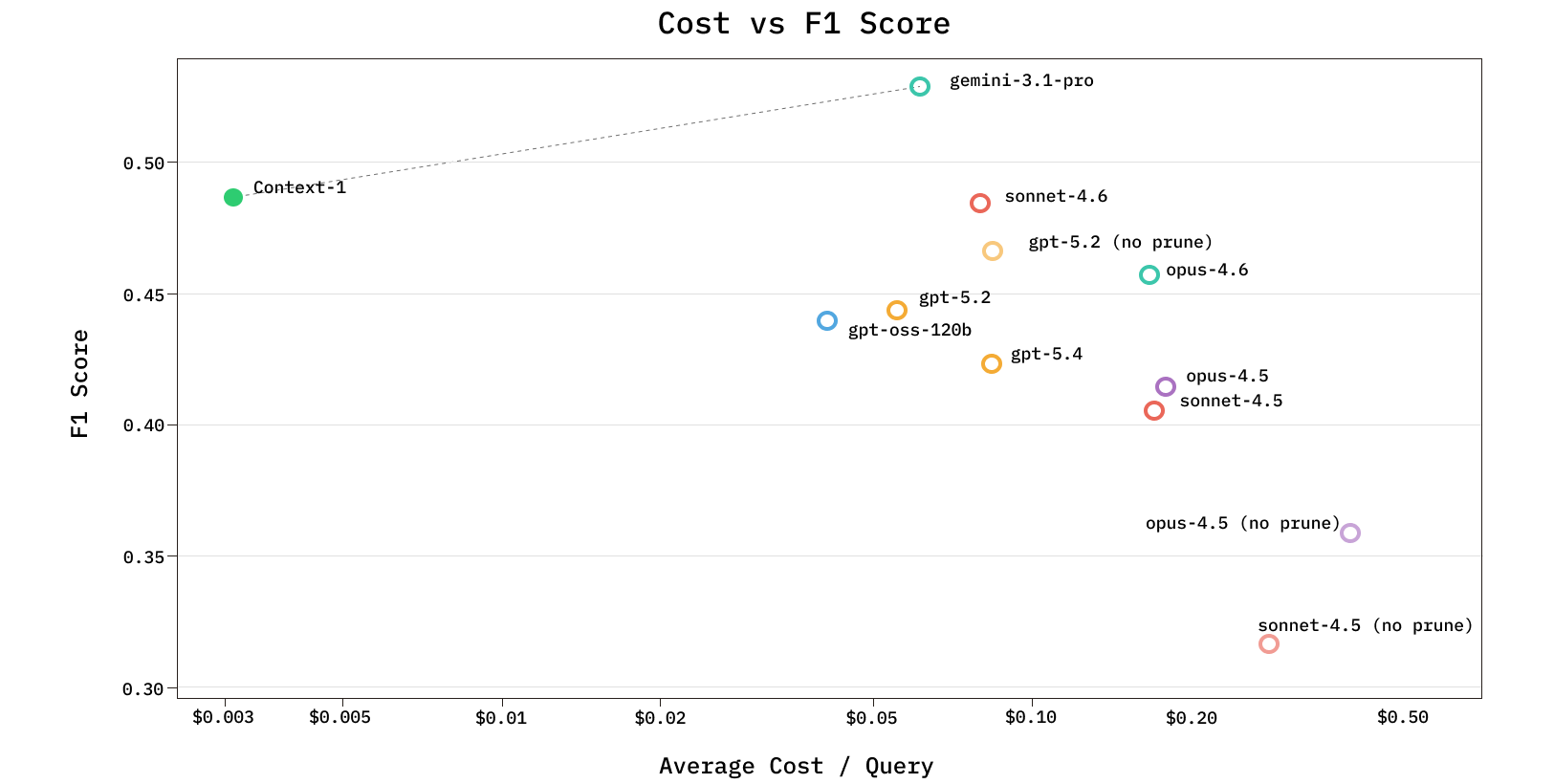
Building on these insights, we trained Chroma Context-1, a 20B parameter agentic search model on over eight thousand synthetically generated tasks. Context-1 achieves retrieval performance comparable to frontier LLMs at a fraction of the cost and up to 10x the inference speed. Context-1 operates as a retrieval subagent: rather than answering questions directly, it returns a ranked set of supporting documents to a downstream answering model, cleanly separating search from generation. The model is trained to decompose a high-level query into subqueries and iteratively search a corpus across multiple turns. As the agent's context window fills, it selectively discards irrelevant results to free capacity and reduce noise for further exploration.
In this work we present our synthetic data generation pipeline, agent harness, and training methodology alongside a comprehensive evaluation of Context-1 across a range of retrieval benchmarks. Our results demonstrate that a purpose-trained 20B model can reach the Pareto frontier of retrieval performance with respect to cost and latency, matching or exceeding frontier models that are orders of magnitude larger at a fraction of the compute.
Key Techniques#
We present the following:
- A staged training curriculum that first optimizes for recall before shifting toward precision, training the agent to progressively narrow from broad retrieval to selective retention. We release the weights of this model to the public under a permissive Apache 2.0 license.
- A context management strategy in which the agent selectively edits its own context during search, discarding irrelevant passages to free context capacity for further exploration and to reduce the effects of context rot.
- A scalable synthetic task generation pipeline that uses a human-aligned LLM judge to minimize the need for human annotation while maintaining task quality. We release the full codebase for this pipeline to support reproducibility and further research.
Related Work#
The limitations of single-shot retrieval have driven substantial exploration into agentic search systems, in which reasoning is interleaved with retrieval to resolve queries that require satisfying multiple constraints jointly or following a chain of dependent clues across documents. These systems vary in their termination strategy: some run for a fixed number of turns, while others terminate dynamically based on a learned sufficiency signal. By shifting control of the retrieval strategy to the model itself, these systems can reformulate queries based on intermediate results, decide when to explore versus exploit, and terminate search based on a confidence assessment. These systems model search as a sequential reasoning task, in which the right next query depends on what has been found so far. Benchmarks such as InfoDeepSeek, evaluate agentic information seeking in dynamic web environments, provide controlled testbeds for measuring multi-turn retrieval quality. However, most existing agentic search systems rely on frontier-scale models to drive the retrieval loop, making them expensive and latency-intensive to deploy at scale.
To overcome the limitations of using a single model for both retrieval and generation, recent work has explored separating these roles through subagent architectures. Anthropic's multi-agent research system uses an orchestrator that spawns parallel subagents to explore different facets of a query; their internal evaluations showed the multi-agent approach outperforming single-agent Claude Opus 4 by 90% on research tasks, with token usage alone explaining 80% of the performance variance. This suggests that decomposing search into specialized subagents is a promising architectural direction, though the cost implications of running frontier models as subagents remain a practical barrier.
A key practical challenge for any multi-turn search agent is managing the context that accumulates over successive retrieval steps. As the agent gathers documents, its context window fills with material that may be tangential or redundant, increasing computational cost and degrading downstream performance - a phenomenon known as context rot. In MemGPT, the agent uses tools to page information between a fast main context and slower external storage, reading data back in when needed. Agents are alerted to memory pressure and then allowed to read and write from external memory. SWE-Pruner takes a more targeted approach, training a lightweight 0.6B neural skimmer to perform task-aware line selection from source code context. Approaches such as ReSum, which periodically summarize accumulated context, avoid the need for external memory but risk discarding fine-grained evidence that may prove relevant in later retrieval turns. Recursive Language Models (RLMs) address the problem from a different angle entirely, treating the prompt not as a fixed input but as a variable in an external REPL environment that the model can programmatically inspect, decompose, and recursively query. Anthropic’s Opus-4.5 leverages context awareness - making agents cognizant of their own token usage as well as clearing stale tool call results based on recency.
These approaches demonstrate the necessity and importance of active context management, but do not address the specific problem faced by a multi-turn retrieval agent: selectively retaining or discarding retrieved documents based on evolving relevance judgments, without compressing evidence into lossy summaries, relying on external memory infrastructure, or requiring inference-time scaffolding that may offset the efficiency gains of a smaller model.
One promising direction for reducing cost and latency is to replace frontier models with smaller, purpose-trained alternatives. WebExplorer trains an 8B web agent via supervised fine-tuning followed by RL that searches over 16 or more turns, outperforming substantially larger models on BrowseComp. Cognition's SWE-grep trains small models with RL to perform highly parallel agentic code search, issuing up to eight parallel tool calls per turn across just four turns and matching frontier models at an order of magnitude less latency. Search-R1 demonstrates that RL alone can teach a language model to perform multi-turn search without any supervised fine-tuning warmup, while s3 shows that RL with a search-quality-reflecting reward yields stronger search agents even in low-data regimes. However, none of these small-model approaches incorporate context management into the search policy itself, and existing context management methods that do operate during multi-turn search rely on lossy compression rather than selective document-level retention.
Training such specialized models requires large volumes of high-quality task data, which motivates the need for synthetic data generation for agentic search. BrowseComp has become a widely-used benchmark for evaluating such capabilities, consisting of challenging yet easily verifiable deep research tasks. However, its reliance on dynamic web content makes evaluation non-reproducible across time. BrowseComp-Plus addresses this by pairing each task with a static corpus of positive documents and distractors, enabling reproducible evaluation, though the manual curation process limits scalability. WebExplorer’s “explore and evolve” pipeline offers a more scalable alternative: an explorer agent collects facts on a seed topic until it can construct a challenging question, then an evolution step obfuscates the query to increase difficulty. While fully automated, this pipeline lacks a verification mechanism to ensure the accuracy of generated document pairings. This is critical for training data, in which label noise directly degrades model quality. Additionally, existing synthetic generation methods have mostly been applied in the web search domain, leaving open whether they can scale across the diverse range of domains where agentic search is deployed.
Synthetic Task Generation#
End-to-end search builds on two core capabilities:
- Planning - effective search requires decomposing a high-level goal into a sequence of queries, often starting broad and narrowing based on intermediate results.
- Evaluation - at its core, search is about identifying what matters given a goal and information seen so far. Accurate search requires identifying relevant information amongst noise, distinguishing them from distractors.
Our generated tasks target these two fundamental capabilities. We acknowledge that they are not comprehensive and do not represent realistic end-to-end search tasks; the simplistic approach here is intentional, allowing us to isolate and train for these core skills.
We generate questions in the style of BrowseComp, a benchmark from OpenAI focused on deep research tasks designed to be difficult to solve but easy to verify.
A book that was once a contender for an award, originally created in the 2000s (the award itself), was translated into over twenty five languages. In the 2010s, the year in which this book was published, another book, which had been released the preceding year, won the very award above for which the first book was later in contention. The author of this prize-winning book was born in the same city where the author of the initially mentioned book grew up. Based on this connection, in what city was the author of the first book born?
These questions require a plan by decomposition: searching for all criteria simultaneously is unlikely to succeed, so an effective agent must break the problem into subqueries, search broadly for individual criteria, and refine as information surfaces.
This process also requires careful relevance judgment. Each query surfaces multiple results, and context accumulates quickly. Some documents may appear relevant but fail to satisfy all criteria, such as a book translated into 25+ languages but contending for an award in the 1980s rather than the 2010s. Distinguishing these distractors from truly relevant documents is essential.
Our benchmark task creation pipeline generates multi-constraint questions across four domains: web, finance, legal, and email. While the generation process varies by domain, all follow a shared structure.
- Gather supporting documents — containing unique facts, using domain-appropriate search tools.
- Generate clues (obfuscated references to facts) — a question combining these clues, and the corresponding answer.
- Verify that the task is valid — do the supporting documents actually support the clues and lead to the final answer?
- Optionally, collect distractors — documents that satisfy some criteria but point to a different answer.
- Optionally, recursively chain — bridge the answer of an existing task to a new task with a new final answer, controlling the number of hops required.
Given a seed topic, an agent explores the web and collects documents containing unique, verifiable facts.
The walkthrough above uses the web domain as a concrete example. Given a seed topic sampled from random Wikipedia titles, we provide an agent with web search and scraping tools to explore and collect documents containing unique facts. Using the collected documents, the agent generates clues, a question, and an answer in a single loop. We find that with few-shot examples of ideal queries and instructions for obfuscation, a single agent pass generates challenging tasks without the separate evolution step used in WebExplorer. Full details for all four domains, along with LLM-judge alignment metrics, are provided in the appendix.
Task Verification and LLM Judge Alignment#
A key concern in synthetic data generation is label quality: if supporting documents do not actually support the clues, or distractors inadvertently contain the answer, training signal degrades. Simply asking a model to score a document as relevant can be unreliable, and human labeling is costly since it requires reading each document thoroughly. We overcome these challenges with an extraction-based verification pipeline.
For each supporting document, we prompt an LLM to extract two sets of quotes: document quotes (verbatim spans from the source text) and clue quotes (the corresponding spans from the generated clues). We normalize (i.e. lowercasing, stripping excess whitespace, etc.) both and confirm that the document quotes actually appear in the source document, grounding the relevance judgment in textual evidence rather than model opinion. If any supporting document lacks matching quotes, or if no document contains the answer, we filter out the task.
This reduces human verification to checking whether each document quote supports its paired clue quote, rather than reading entire documents. For distractors, we run a complementary check: given a document and the answer, we extract any occurrence of the answer in any form, filtering out distractors that inadvertently contain it. Across all domains, we achieve >80% alignment accuracy, meaning a human labeler and LLM judge agree on assessments more than 80% of the time.
Task Definition & Evaluation#
Concretely, each task consists of a set of clues, a question, an answer, and a set of supporting documents.
In this task, the agent must return a set of documents it determines to be the most relevant. Using our set of target relevant documents, we evaluate success primarily with four output-level metrics and one trajectory-level metric.
Output-level metrics
- Final answer found: a document (or if necessary, the documents) containing the final answer appeared in the agent's output set.
- Recall: the fraction of positive documents the agent outputted of the total set of positive documents.
- Precision: the fraction of returned documents that are actually relevant.
- F1: harmonic mean of recall and precision, providing a more granular measure that balances both.
Trajectory-level metric
- Trajectory recall: the fraction of target documents encountered at any point during the agent's search, regardless of whether they appear in the final output.
High recall is desirable, but a search agent could trivially maximize it by outputting every document it encounters. Precision measures the opposite: the fraction of returned documents that are relevant. Perfect precision is achievable by returning a single correct document, but at the cost of missing everything else. Evaluating the F1 score strikes a balance.
These two metrics evaluate the quality of the agent's final output, but they do not reveal the source of failure. To disentangle search quality from final selection quality, we additionally measure trajectory recall. Comparing trajectory recall to output recall reveals whether the agent encountered relevant documents during search but failed to include them in its final output, or whether it missed them entirely.
Final answer found is a binary score determined by whether the final answer exists in the set of output documents. The set of documents containing the final answer is a subset of the total set of supporting documents. Thus, it is possible that the agent finds the final answer without finding all the supporting documents. We consider finding the final answer a successful conclusion to a rollout because the agent may come across the final answer without needing to verify all the clues exhaustively. Continued searching may yield valuable results, but given that the final answer is found, continuing to search would be solely for extra verification. While exhaustiveness is useful in select cases, many situations do not require it. As such, we deliberately did not optimize for this behavior.
An alternative evaluation approach would be to provide the retrieved documents into a reasoning model and check whether it produces the correct answer end-to-end. We deliberately avoid this for two reasons. First, it confounds search quality with reasoning quality: if the downstream model fails to answer correctly, it is ambiguous whether the search agent retrieved insufficient evidence or the reasoning model failed to use what was provided. Final answer found isolates the search agent's contribution — if a document containing the answer appears in the output set, the retrieval succeeded regardless of the downstream models performance. This separation is further justified by benchmarks like BrowseComp-Plus, where oracle performance given all supporting documents is high, indicating that the accuracy bottleneck on this style of task is search rather than reasoning. Second, keeping a reasoning model out of the loop is practical: during RL training, every rollout would require an additional LLM call per episode, adding cost and latency that scale with the number of trajectories per step.
Agent Harness#
Context-1 operates as a search subagent focused on retrieving supporting documents for a downstream frontier reasoning model. The agent interacts with the underlying search infrastructure through structured tool calls in an observe-reason-act loop, where each cycle consists of the model producing a tool call (or a final answer), the harness executing the call against the database, and the result being appended to the trajectory as the next observation.
Tools
The agent has access to four tools
| Tool | Description |
|---|---|
| search_corpus(query) | Hybrid BM25 + dense vector search via reciprocal rank fusion (RRF) over a Chroma collection. 50 candidates are retrieved, and then reranked. The top results are returned within a token budget. |
| grep_corpus(pattern) | Regex search over the corpus. Returns up to 5 matching chunks. |
| read_document(doc_id) | Read the full content of a document by ID. Chunks are reranked and truncated to fit the remaining token budget |
| prune_chunks(chunk_ids) | Removes specified chunks from the conversation context |
The search_corpus tool queries both sparse vectors and dense embeddings in each Chroma collection. A search issues both queries in parallel, and the results are fused via reciprocal rank fusion (RRF) to combine the strengths of keyword and semantic matching. The top 50 fused results are scored by a reranker, which selects the top results within a per-call token budget.
Deduplication
A common failure mode in multi-turn search is re-retrieving the same documents. This is due to how agents will often issue the same keywords in their search trajectory. To counter this, our agent harness tracks every chunk ID encountered across all prior search calls and passes them as exclusion filters on subsequent searches. This forces each search to surface new information and improves exploration efficiency.
Token budget management To mitigate the impact of context rot we bound the context window to a fixed token budget . A single search call can return up to tokens of chunk content. After searches, the context window is exhausted. This presents a tradeoff: the agent must accumulate evidence to answer complex queries, but it cannot keep everything. Context-1's harness leverages several mechanisms to make the agent aware of and able to actively manage its context.
- Continuous visibility — After every turn, the current token usage is appended to the observation (e.g.,
[Token usage: 14,203/32,768]), ensuring the model always knows how much room it has left. - Soft threshold — When usage exceeds tokens, the harness injects a response message suggesting the model start to prune chunks to free context space or provide its final answer after assessing its state. Search and read results are truncated to fit the remaining budget, and a reserve is maintained for the model's next response. This message is shown only during training rollouts.
- Hard cutoff — Beyond a configurable cutoff in between and tokens, all tool calls except prune_chunk are rejected outright, returning an error message directing the model to prune or conclude.
Pruning
When the model calls prune_chunks, the harness removes the specified chunks from the model's view but preserves the full unpruned trajectory for reward computation. This is critical for the reward described below, which credits the agent for documents it encountered during search even if they were later pruned.
As the token budget fills, the agent's action space narrows: early turns allow unrestricted search, the soft threshold introduces pressure to prune, and the hard cutoff restricts the agent to pruning or concluding. This creates pressure to be selective: past the soft threshold, retrieving new evidence requires freeing space by discarding existing results.
Model Training#
Agent abstraction
The agent harness is implemented as a provider-agnostic state machine with three operations: observe, infer, and act. The agent maintains a trajectory, an ordered sequence of observations and actions, that grows over the course of an episode. At each step, observe appends a new observation (a tool result or the initial prompt) to the trajectory. Infer passes the trajectory through a pluggable inference model and returns the next action (one or more tool calls, or a final text response). act records the action in the trajectory, executes any tool calls, and returns the resulting observation. The loop terminates when the model produces a text-only response with no tool calls, or when the trajectory exceeds a maximum length.
agent.reset()agent.observe(initial_observation)while not agent.is_done:action = agent.infer()observation = agent.act(action)if observation is not None:agent.observe(observation)trajectory = agent.trajectory
The inference backend is an abstract interface: given the current trajectory and toolset, it returns one or actions or a final response. We implement this interface for multiple models and response formats, allowing the same agent loop, tools, and context management logic to be reused across SFT data generation, RL training, and evaluation without modification. The agent class hierarchy supports behavior composition, enabling rapid experimentation with different search strategies. Investing in this level of abstraction upfront pays off quickly: new search strategies, model backends, or tool configurations can be rapidly iterated on and tested.
SFT#
Before reinforcement learning, we perform a supervised fine-tuning warmup to produce well-formed tool calls, follow the retrieval subagent prompt format and learn strong behavior priors such as parallel tool calling and query decomposition. We generate SFT trajectories by running the full agent loop with large models such as Kimi K2.5 as the inference backend. Each rollout produces a complete trajectory: the initial prompt, the model's reasoning and tool calls at each turn, the tool results, and the final document set.
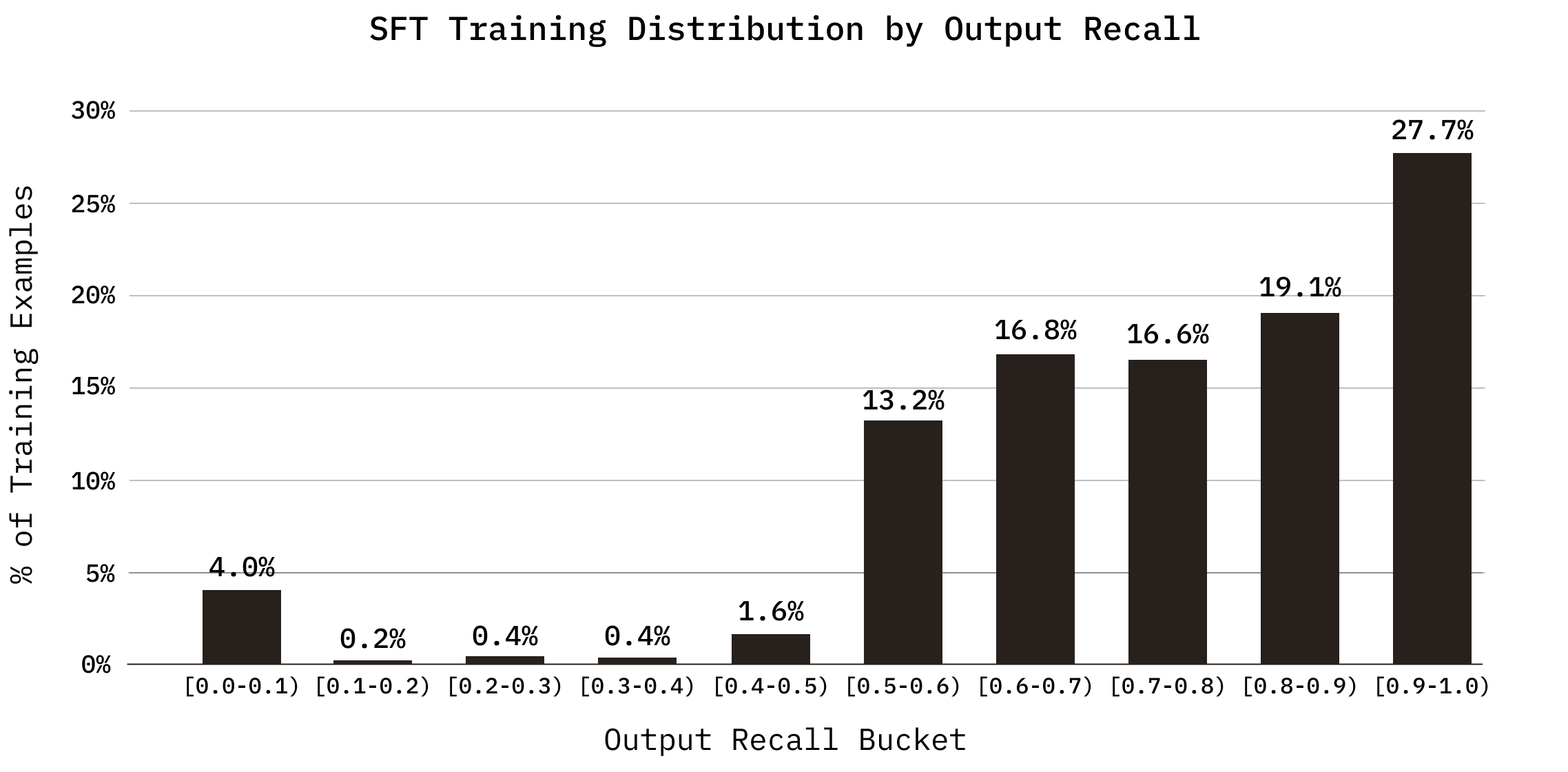
These trajectories are filtered before training based on two recall metrics: trajectory recall (the fraction of target chunks encountered at any point during search) and output recall (the fraction of target chunks present in the final document set). We include both successful and unsuccessful rollouts in the SFT dataset. This is motivated by Shape of Thought, which demonstrates that training on synthetic traces from more capable models improves performance even when all traces lead to incorrect final answers, as the distributional properties of the traces matter more than the correctness of every individual step. In our setting, low-recall trajectories still contain well-formed tool calls, query decompositions, and pruning decisions that provide useful behavioral signals.
Rollouts are filtered by recall quality. Trajectories with high recall (above 50% trajectory recall and 40% output recall) are retained in full. Those with lower recall are included at a diminishing rate. A small fraction (up to 5%) of zero-recall trajectories are included as negative examples, deduplicated by query, to expose the model to failure modes, long rollouts, and potentially valid abstentions without letting them dominate the training signal. Trajectories where the model explored well but concluded poorly (where trajectory recall substantially exceeds output recall) are excluded entirely, as training on them would reinforce the disconnect between exploration and selection. When multiple rollouts for the same query achieve high output recall, only one is kept to prevent overrepresentation of easy queries. Malformed outputs are discarded.
RL#
After SFT we leverage reinforcement learning with verifiable rewards (RLVR). The base model is gpt-oss-20b, adapted via a LoRA. We selected gpt-oss-20b for its fast inference under MXFP4 quantization, strong oracle retrieval performance on common benchmarks, and strong ecosystem support.
Training
We train Context-1 fully on-policy using CISPO, a variant of GRPO. At each training step, 128 queries are drawn from a shuffled, interleaved mixture from training splits of our legal, patent, and web generated queries only. For each query, 8 independent environment instances are created for rollout, yielding 1,024 agent trajectories per step.
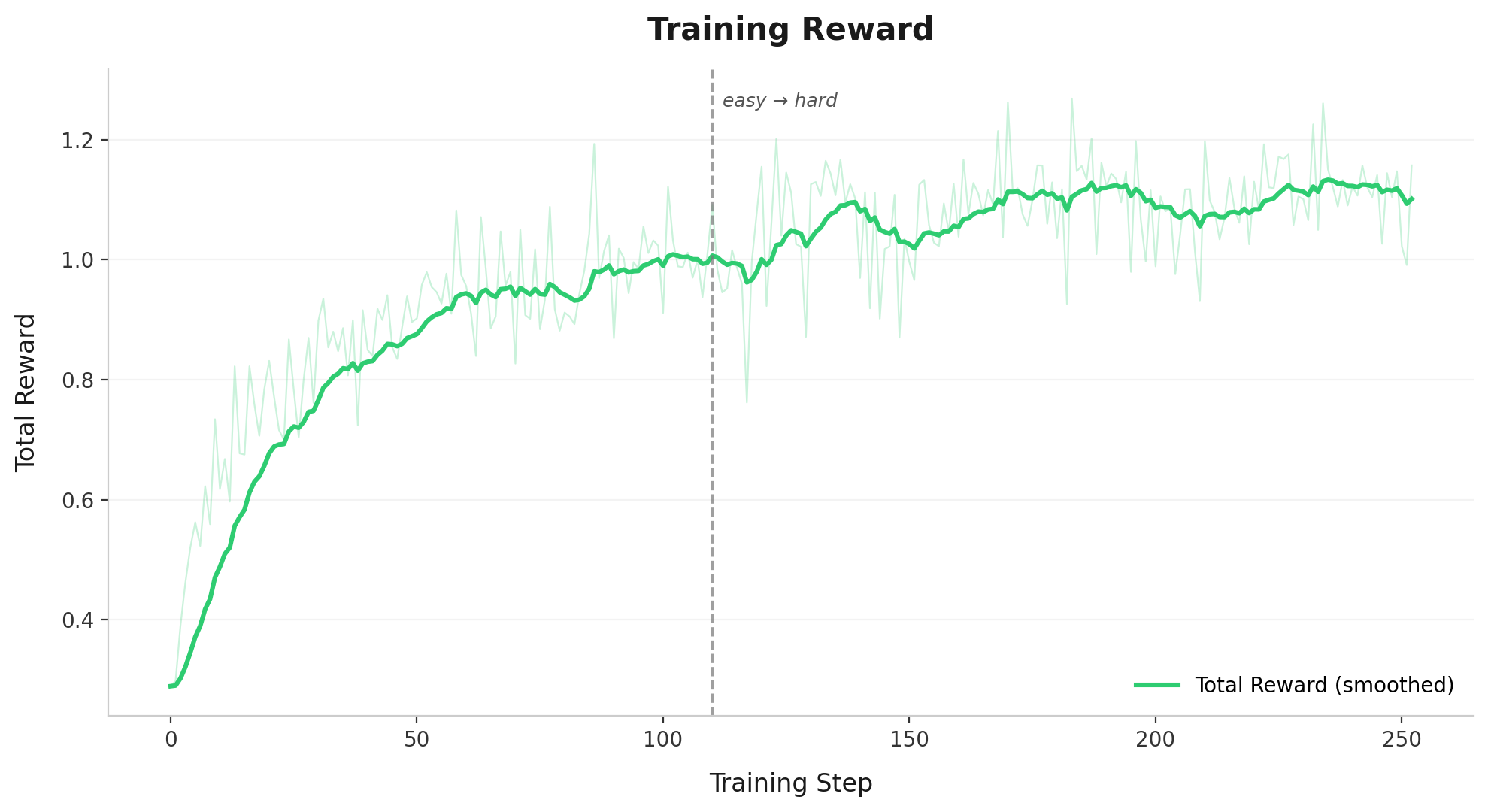
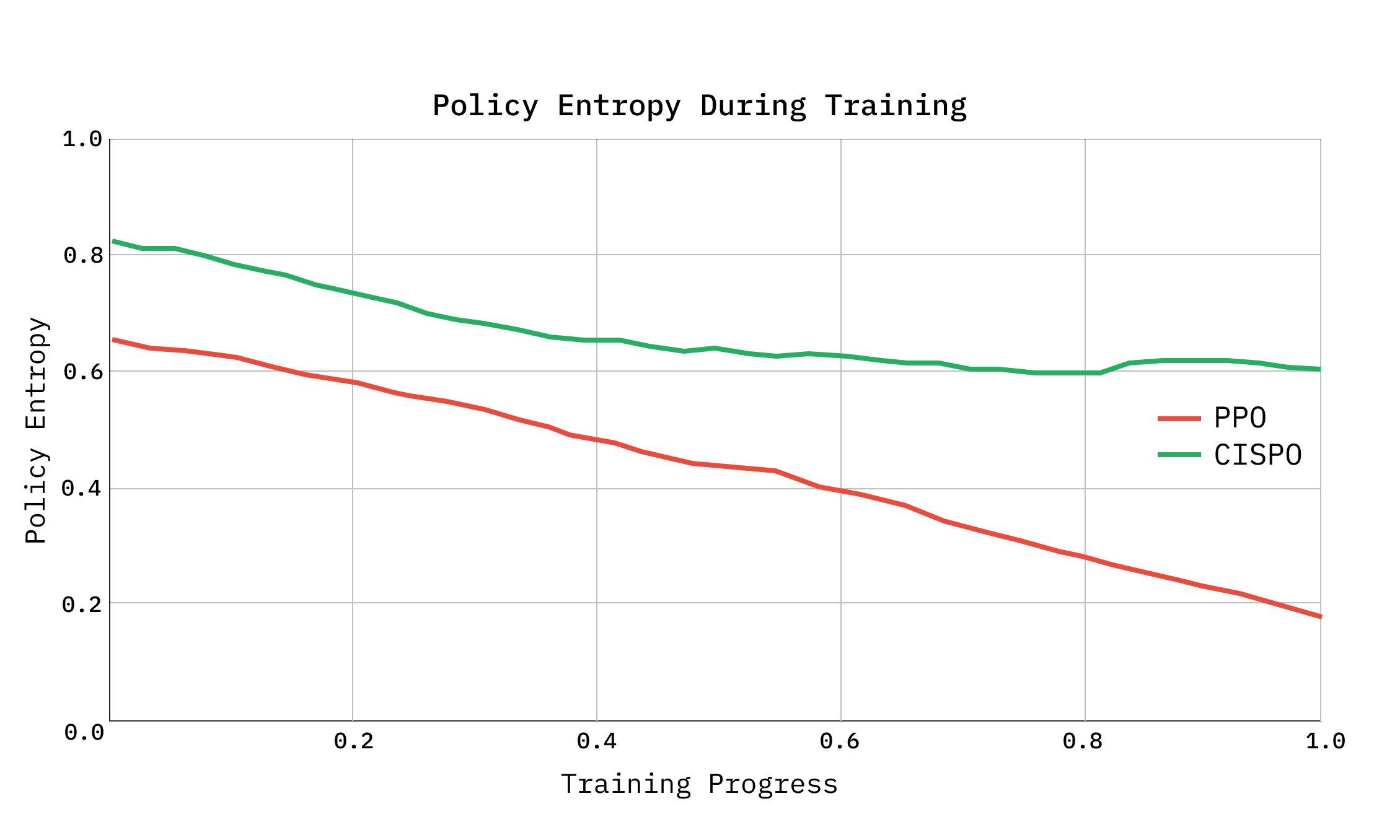
At episode end, each environment computes its reward. Groups in which all 8 rollouts receive identical rewards are discarded, as they provide no gradient signal under within-group normalization. CISPO loss is then computed over the remaining groups, and 4 substeps of gradient descent are applied to the LoRA parameters. We train over our dataset for 5 epochs, for a total of ~300 possible steps, and observe convergence around 230 steps as detailed in the figure below.
Policy loss
We use CISPO (Clipped Importance-Sampled Policy Optimization) as suggested by ScaleRL, a variant of GRPO that clips the importance sampling weights rather than the surrogate objective.
In standard GRPO, tokens whose importance ratios fall outside the clip range receive zero gradient; CISPO instead detaches the clipped weights and uses them as scaling coefficients on the log-probability gradient, ensuring all tokens contribute to learning, including rare but critical tokens such as pruning decisions and query reformulations. Advantages are computed via within-group normalization, where each query's 8 rollouts compete and only their relative rewards determine the gradient.
We found the use of CISPO to be critical for preventing entropy collapse as we scaled up the number of training steps. We initially experimented with the unbiased loss suggested in Dr GRPO as well as adopting clip-higher from DAPO. Aligned with the findings in ScaleRL, we found CISPO to be the most robust to entropy collapse and lead to the highest sample efficiency.
Reward design
The reward combines an outcome signal, a process component, a binary bonus and penalties for degenerate behavior.
The outcome component is an score with at initialization, weighting recall sixteen times more than precision. This bias reflects Context-1's role as a retrieval subagent feeding a downstream answering model: missing a critical document is often worse than including an irrelevant one, since the downstream model can still filter but cannot recover information that was never retrieved.
For some datasets, evaluation operates at fact granularity rather than document granularity; a fact is counted as found if any of its associated chunks appear in the retrieved set, since at dataset construction time, the same fact may be found in multiple documents. This is detailed further in our dataset generation methodology.
The process component trajectory recall, which credits the agent for encountering relevant documents during search regardless of whether they appear in the final output.
Without this term, the agent can converge to a degenerate strategy of issuing one or two broad searches and terminating early with whatever is returned. The trajectory recall signal ensures that exploration is rewarded even when explored documents are subsequently pruned, which is particularly important given that pruning decisions are imperfect, especially early on in training.
The final answer bonus, is a binary +1.0 for retrieving a chunk directly containing the answer rather than supporting evidence. Without this bonus, training on alone can incentivize agents to retrieve topically related documents without locating the answer itself.
Two additional penalties address degenerate behaviors. A repeated pruning penalty, , of 0.1 per excess call is applied to consecutive prune streaks longer than 3 (capped at 0.5), discouraging the agent from pruning one chunk at a time across many turns rather than batching. A turn count penalty, , increases linearly from 0 at 64 turns to 0.5 at 128 turns, discouraging trajectories with diminishing-return searches. The final reward is floored at for any trajectory that completes without error and capped at the pre-penalty value, , ensuring that successful trajectories always dominate failed ones while preventing the floor from inflating penalized rewards.
Curriculum
We structure two curricula over the course of training.
First, a difficulty curriculum across rollout phases. Our synthetic datasets label each datum by difficulty according to the number of hops required. Our training is divided into two phases across these difficulty levels as demonstrated in Beyond Ten Turns. During the first phase, the query distribution is skewed toward lower-difficulty questions. In the second phase, the distribution shifts toward higher-difficulty multi-hop tasks that require extended search trajectories and pruning cycles. This phasing allows a reasonable policy to be learned before exposing the model to problems where near-zero reward is likely without an already-competent search policy.
Second, a reward curriculum via . Between epochs, the parameter in the reward is annealed from recall-focused, weighting recall 16x more than precision toward weighting recall 4x more. Early in training, the recall bias encourages broad exploration: the model is rewarded for finding relevant documents regardless of how much noise it accumulates. As training progresses and the model becomes competent at searching and pruning, is shifted toward precision, encouraging the model to be more selective in what it retains in its final output.
Scaling search infrastructure for RL rollouts
A single training step produces tens of thousands of search requests across 1,024 trajectories executing tool calls in parallel, with peak concurrency at 3,000+ queries per second as environments cycle between model inference and tool execution. To handle this load, each Chroma collection is replicated internally on Chroma Cloud, with each tool call randomly selecting a replica. The replication factor was chosen empirically to keep query latency manageable under peak rollout load. No failures were observed from our search infrastructure during training, removing that as a potential source of instability during large scale parallel rollouts.
Model Behavior#
Training gives rise to several behaviors in Context-1 that are conducive to effective search.
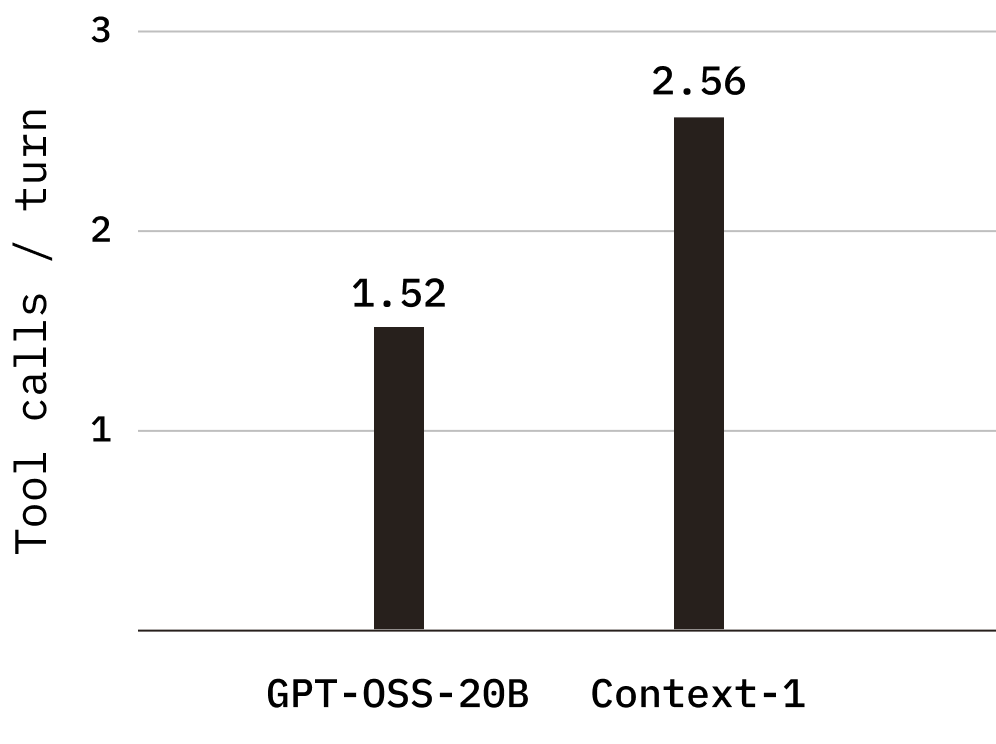
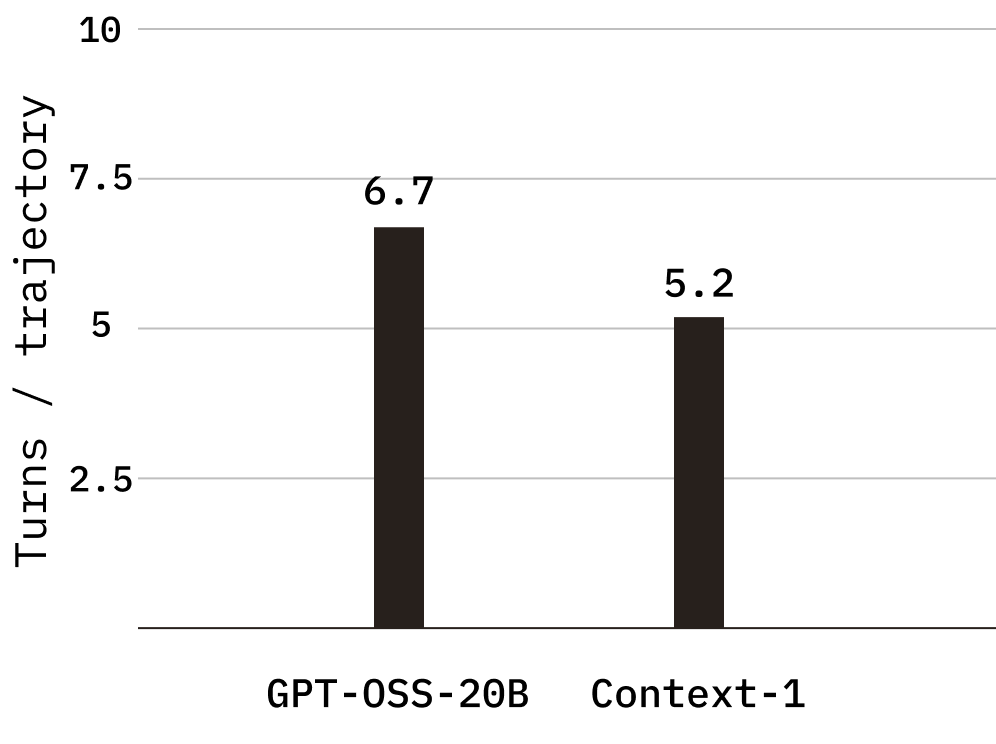
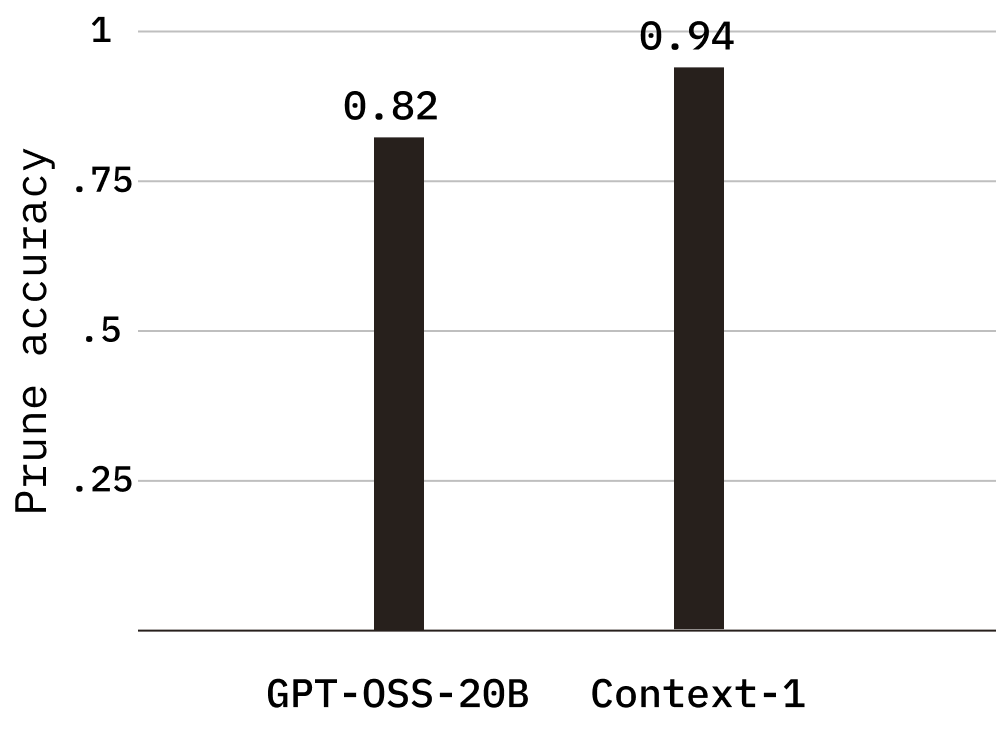
Parallel tool calling
Context-1 makes significantly greater use of parallel tool calls, averaging 2.56 tool calls per turn compared to 1.52 for the base model on tasks the base model is able to complete. This increase in per-turn throughput reduces the number of turns required to complete a task, from an average of 6.7 turns per trajectory in the base model to 5.2 in Context-1, directly contributing to lower end-to-end latency and cost.
Prune accuracy
We also observe a substantial improvement in prune accuracy, which measures whether the agent correctly identifies irrelevant documents for removal. Context-1 achieves a prune accuracy of 0.941, up from 0.824 in the base model, indicating a meaningfully sharper ability to discard noise and retain signal.
Planning
Finally, Context-1 demonstrates significantly improved planning capabilities. The model’s reasoning traces suggest greater clarity and structure in its chain of thought, enabling it to decompose complex queries more effectively before acting.
Before (gpt-oss-20b)
We need to retrieve documents that contain the answer to the question: "What is the name of this award?" The award is a high recognition for battlefield valor, established in the late eighteenth century, and a ceremony took place at a southern port where a high-ranking officer who had commanded a vessel that was attacked during that operation personally conferred a distinction upon one of the attackers. The context: a naval officer participated in an underwater operation in the eastern Mediterranean during the winter of the early nineteen-forties. That suggests WWII operations. Underwater operation in eastern Mediterranean: likely German U-boat operations? But the phrase "naval officer participated in an underwater operation" could refer to an underwater operation like the Italian or British, or perhaps a submarine assault. "Eastern Mediterranean during the winter of the early nineteen-forties" might be Operation Kittiwake? Actually, let's think: "Underwater operation" could be an operation like Operation Bernhard? No, that's a different war…
After (Context-1)
Let me break down this query to understand what I need to find:
The query is asking for the name of an award. Let me parse the clues:
1. A naval officer participated in an underwater operation in the eastern Mediterranean during the winter of the early 1940s.
- This would be during World War II, so early 1940s = 1940-1943 or so.
- Eastern Mediterranean = could be around Greece, Turkey, Lebanon, Syria, Cyprus, Crete, etc.
- Underwater operation = likely submarine warfare or naval mine-laying, etc.
2. Years after hostilities ended (after WWII, so post-1945), a ceremony took place at a southern port.
- Southern port - could be in the US, or southern Europe, or somewhere else.
3. At this ceremony, a high-ranking officer who had commanded a vessel that was attacked during that operation personally conferred a distinction upon one of the attackers.
- So there was a vessel attacked during the underwater operation in early 1940s.
- The commander of that vessel, years later, awarded someone (the attacker) a distinction.
4. This particular honor was established in the late eighteenth century, represents the highest recognition for battlefield valor in its country of origin.
- Established in late 18th century = 1700s.
- Highest recognition for battlefield valor = this sounds like a military decoration for bravery.
- For a country - likely the US, UK, France, etc.
…
Both traces from the same task (web domain, task 1_0).
When compared to the base model, Context-1 sees improvements across all key evaluation metrics.
| Traj recall | Output Recall | F1 | Final Answer Found | |
|---|---|---|---|---|
| gpt-oss-20b (base) | 0.640 | 0.361 | 0.307 | 0.541 |
| Context-1 | 0.739 | 0.641 | 0.487 | 0.798 |
Inference#
We perform both SFT and RL using a BF16 checkpoint of GPT-OSS 20B and then subsequently perform quantized aware distillation on traces from the higher precision model in order to quantize to MXFP4. At inference time, Context-1 is served via vLLM. The model runs on an Nvidia B200 with MXFP4 quantization for the MoE layers, enabling fast inference despite the 20B total parameter count. The serving layer exposes a streaming API that executes the full observe-reason-act loop, and returns tool calls, observations, and the final retrieved document, allowing downstream applications to render the agent's search process in real time. Under this setup, we reliably obtain 400-500 tok/s end to end.
Results#
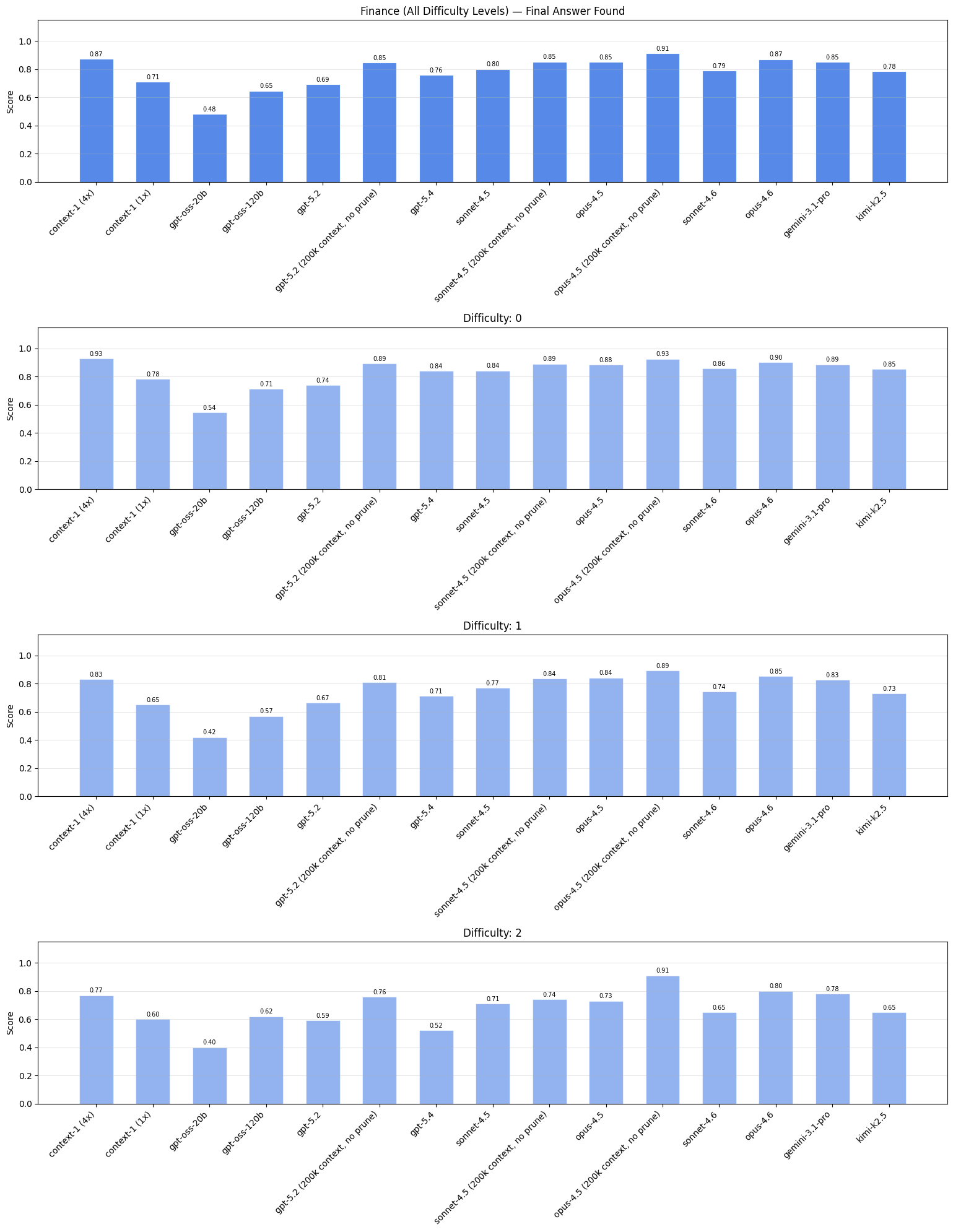
We evaluate Context-1 alongside 10 other models across our generated and public benchmarks, and observe comparable performance with frontier models. Compared with the base model, gpt-oss-20b, Context-1 achieves a substantial improvement across all domains.
For a select subset of frontier models, we also analyze the effect of having a low token budget and prune tool. Specifically, we give these models a token budget of 200k tokens (as opposed to 24k tokens) and remove prune_chunks from its tool set. We refer to these versions as [model] (200k context, no prune). The performance of various models under less constrained budgets and removal of the prune tool varies depending on the base model.
We include evaluation of Context-1 (4x) which is the result of running four rollouts of Context-1 and performing reciprocal rank fusion on the result. Given the low cost and high-throughput of Context-1 running it in a 4x configuration remains cheaper than larger models, and multiple rollouts can be run in an embarassingly parallel fashion.
Generated Benchmarks#
Web#
This web domain benchmark is most similar to BrowseComp, using webpages as the corpus. We chain questions to vary the number of hops required to reach the final answer, with the highest number of hops being 4 hops.
clues: "A sacred structure in a western European capital was designed in a style combining two ancient architectural traditions, selected through a competitive process initiated in the late 1860s. The community for whom this building was constructed gained official state recognition during the early 1830s, shortly after their nation achieved independence. Construction of this edifice was completed during the same year a Belgian ocean liner was launched from an English shipyard on the eve of winter solstice."
question: "On what date was this building formally inaugurated?"
truth: "September 20, 1878"
Finance#
We use publicly available SEC filings from 2025 to generate tasks. We use this recent data to minimize contamination, as most cutoff dates for our evaluated models are in 2025. We also chain questions here up to 3 hops total.
clues: "A company concluded a major work stoppage in late 2024 after union members representing approximately one-fifth of the workforce in a northwestern state voted to approve a new agreement. This agreement replaced an older one that had expired in the early fall season of that year. The shareholders of a major supplier approved merger terms in late winter of the following year."
question: "In what month and year does the new collective bargaining agreement expire?"
truth: "September 2028"
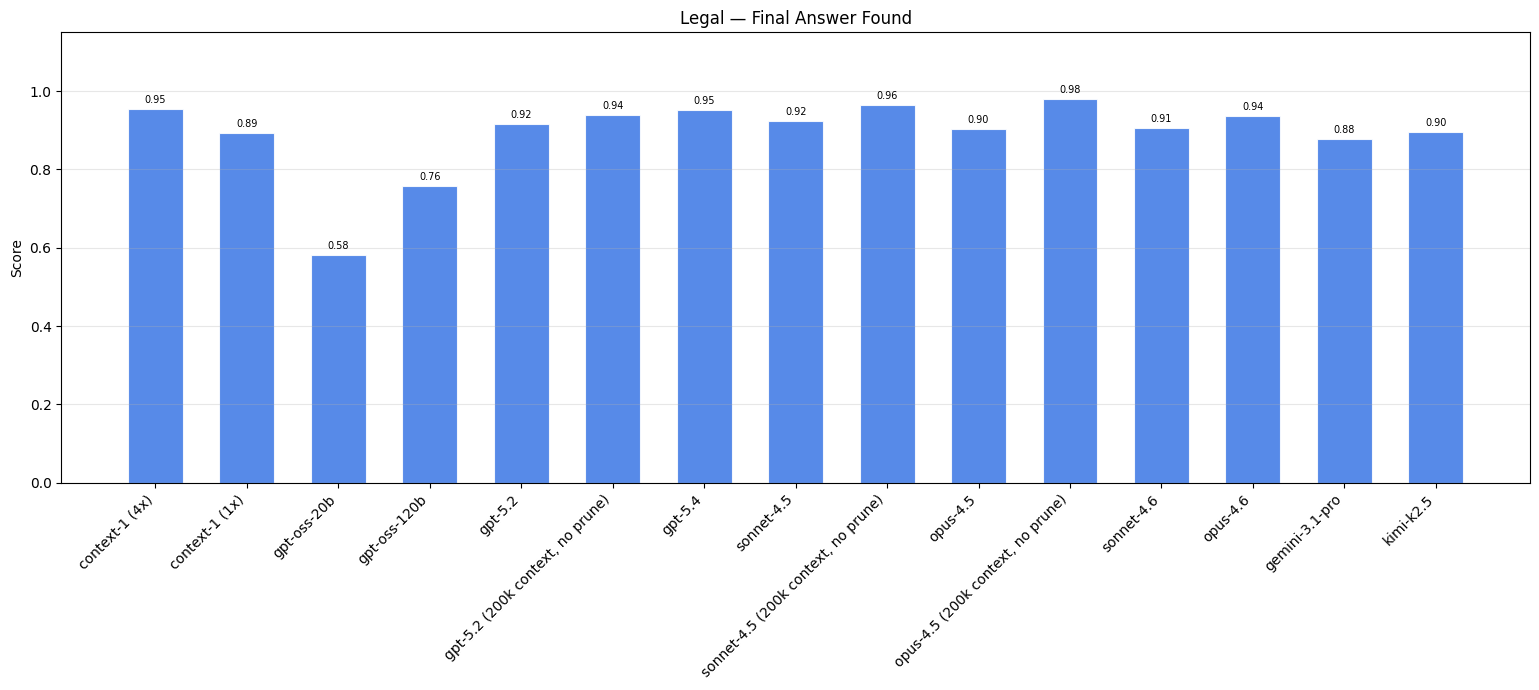
Legal#
Patent examination naturally creates the kind of multi-document reasoning we want to test. When a patent examiner rejects a claim, they must cite specific prior art, which are earlier patents that anticipate the claimed invention. These rejections explicitly connect documents through argued relationships, providing ground-truth links between patents.
Task: [Claim]... This claim is rejected based on Prior Art A. Prior Art A describes a system for authenticating tangible items using a decentralized record-keeping approach. The document covers obtaining spectral emission data from a material when subjected to energy exposure, along with additional identifying information. Prior Art A addresses the cryptographic protection requirement through its description of verification proofs using paired asymmetric encryption credentials, where such proofs can be created and validated to confirm the identity of entities and uniquely identify physical items. Find the prior art matching these details.
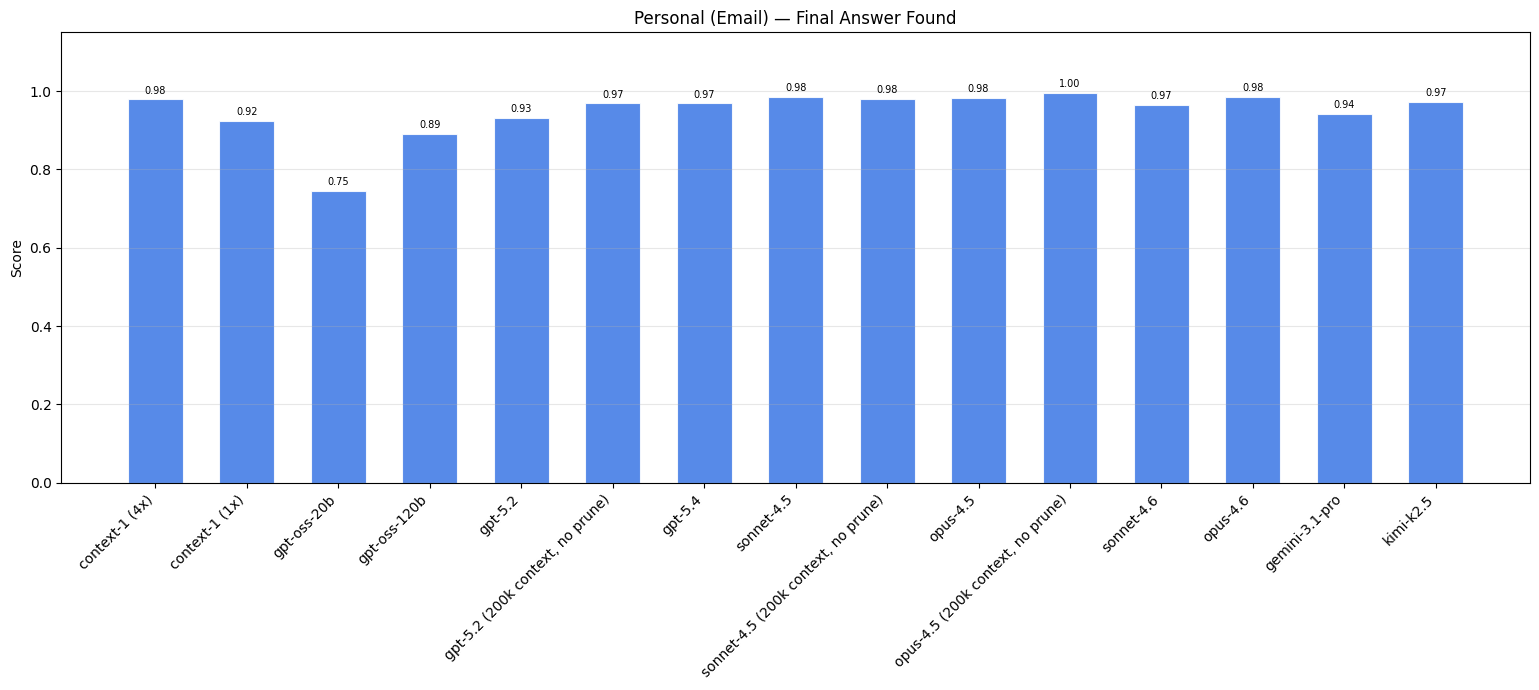
Email#
Emails present distinct challenges for search: they often contain abstract references to shared context, informal language, grammatical errors, abbreviations, and fragmented sentences. To capture this, we use emails from the released Epstein files for task generation. These files were released in November 2025, after the training cutoffs of our evaluated models, ensuring the content is unseen.
To fill our corpus, we use the Enron email dataset: a collection of internal correspondence released during the 2001 Enron investigation. These emails share similar characteristics (informal tone, abbreviations, implicit context) but are widely available and likely present in model training data, making them unsuitable for task generation. Instead, we replace their names and dates, then use them to fill the corpus, increasing retrieval difficulty without contaminating our evaluation targets.
clues: "An individual who has worked on developing operating systems shared an article from a media outlet about a decentralized digital currency gaining acceptance in the nation's capital, noting a specific percentage gain on their holdings. In another thread, a journalist from this same media outlet reached out to a legal professional about a declaration filed in federal court concerning allegations about a former head of state and time spent on an island. This media outlet also published coverage of a controversial tell-all book about an administration, which was referenced when an assistant mentioned being unable to print an article due to lacking a subscription."
question: "Which media organization published all three pieces?"
truth: "Washington Post"
Results#
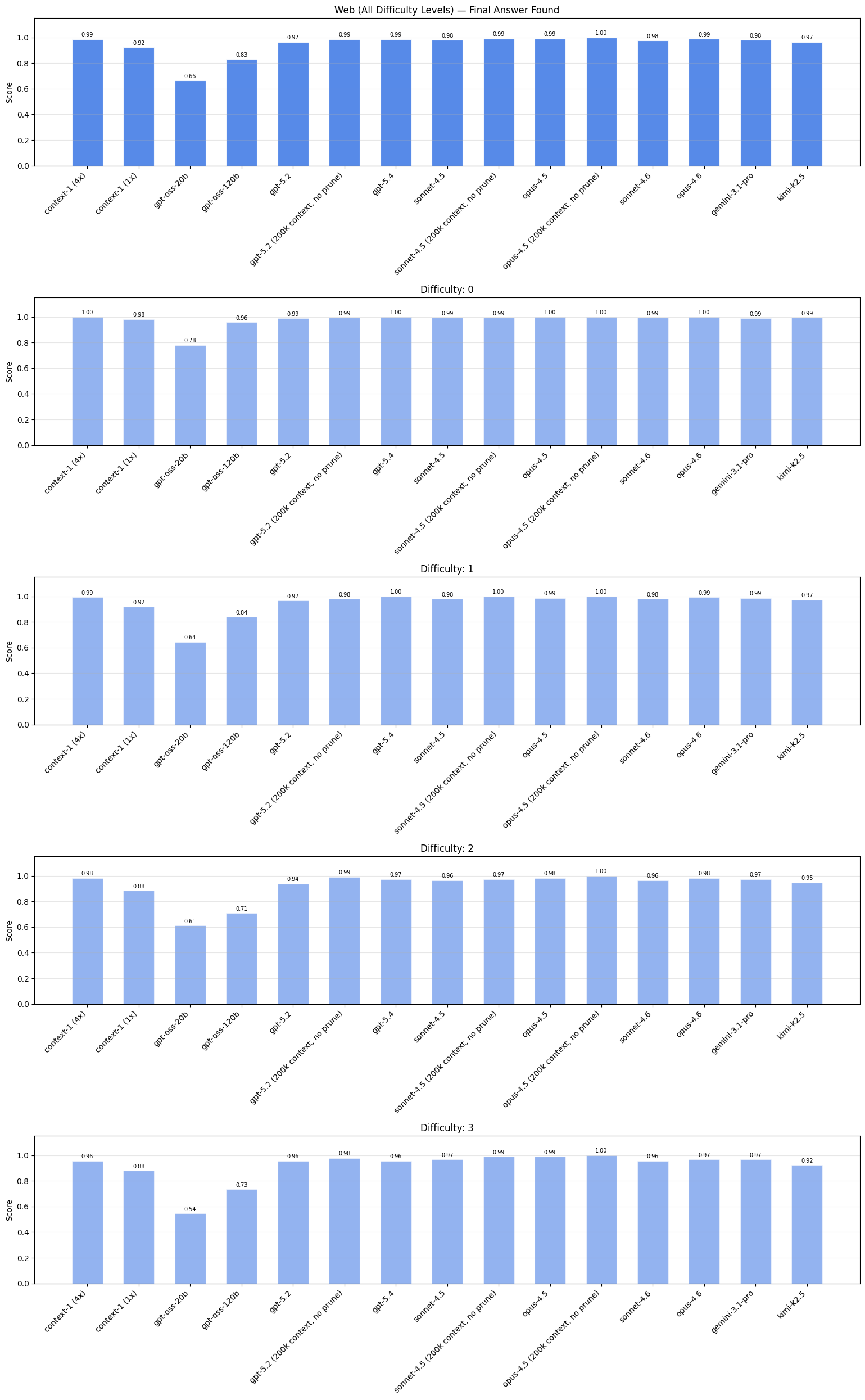
Context-1, especially when considering the 4x version, has similar search performance to the frontier models. Note: web and finance results are filtered for specific difficulty levels due to saturation in lower levels; full results for each difficulty level are detailed in the appendix.
| Model ↕ | Web (Diff. 2+) ↕ | Finance (Diff. 1+) ↕ | Legal ↕ | Email ↕ |
|---|---|---|---|---|
| Context-1 (4x) | 0.97 | 0.82 | 0.95 | 0.98 |
| Context-1 (1x) | 0.88 | 0.64 | 0.89 | 0.92 |
| gpt-oss-20b | 0.58 | 0.42 | 0.58 | 0.75 |
| gpt-oss-120b | 0.72 | 0.58 | 0.76 | 0.89 |
| gpt-5.2 | 0.95 | 0.65 | 0.92 | 0.93 |
| gpt-5.2 (200k, no prune) | 0.99 | 0.80 | 0.94 | 0.97 |
| gpt-5.4 | 0.97 | 0.67 | 0.95 | 0.97 |
| sonnet-4.5 | 0.97 | 0.76 | 0.92 | 0.98 |
| sonnet-4.5 (200k, no prune) | 0.98 | 0.82 | 0.96 | 0.98 |
| opus-4.5 | 0.99 | 0.82 | 0.90 | 0.98 |
| opus-4.5 (200k, no prune) | 0.99 | 0.90 | 0.98 | 0.98 |
| sonnet-4.6 | 0.96 | 0.72 | 0.91 | 0.97 |
| opus-4.6 | 0.98 | 0.84 | 0.94 | 0.98 |
| gemini-3.1-pro | 0.97 | 0.82 | 0.88 | 0.94 |
| kimi-k2.5 | 0.94 | 0.72 | 0.98 | 0.97 |
Despite not explicitly being trained on the email domain, Context-1 still demonstrates a considerable improvement in performance. This highlights how the search skills of Context-1 generalize beyond the domains and specific task formulation it was trained on, which we further explore in the following section on public benchmarks.
The 200k context, no prune versions of the frontier models outperform their token-constrained counterparts. One reason for this is that the token budget constraint often leads to early termination. When the model is constantly asked to prune or terminate, it is more likely to terminate earlier than if it was never asked at all. As a result, the no prune variants issue a larger number of tool calls and retrieved documents, which increases the chance of encountering supporting documents.
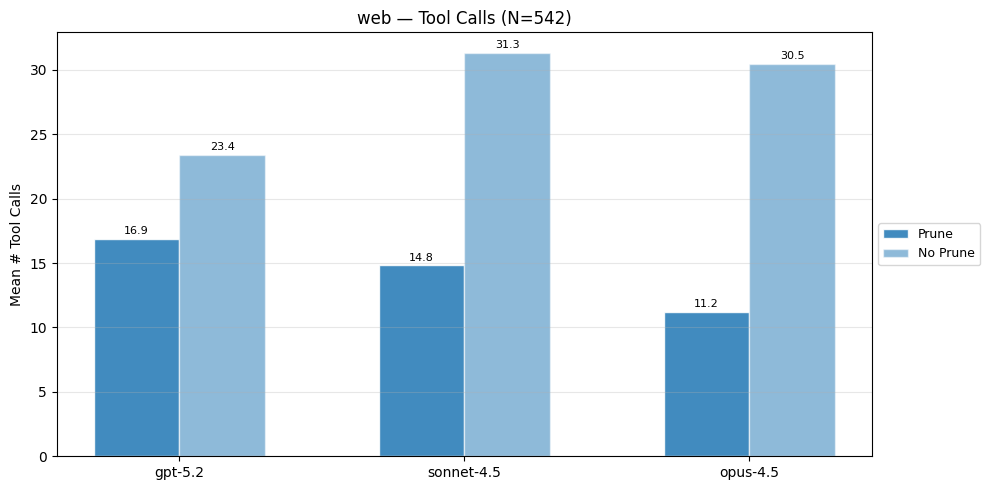
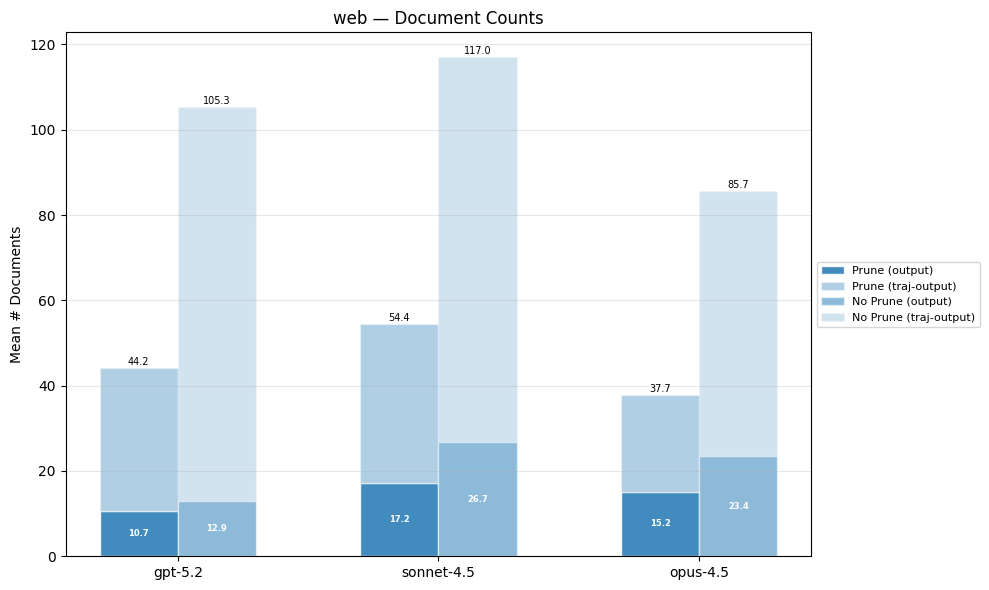
Public Benchmarks#
We also evaluate Context-1 on several existing public benchmarks. While these benchmarks do not fully capture realistic agentic search workflows, they aid in the evaluation of foundational search skills.
Note: Most of the following public benchmarks do not contain a fixed corpus, and instead provide positive URLs and/or ground truth answers. To help focus the task on search rather than on URL replication and tracking, we use a random URL-to-id mapping, assigning virtual document ids to URLs discovered during a search rollout.
BrowseComp-Plus#
BrowseComp-Plus is a benchmark derived from BrowseComp, but with human-verified tasks and a fixed corpus for reproducibility.
A book that was once a contender for an award, originally created in the 2000s (the award itself), was translated into over twenty five languages. In the 2010s, the year in which this book was published, another book, which had been released the preceding year, won the very award above for which the first book was later in contention. The author of this prize-winning book was born in the same city where the author of the initially mentioned book grew up. Based on this connection, in what city was the author of the first book born?
SealQA#
Similar to Browsecomp, SealQA contains challenging questions with easily verifiable ground truth answers. We evaluate on two variants:
- Seal-0 (111 questions): Curated questions iteratively refined until multiple models fail across several attempts. Each question includes positive URLs containing supporting information.
- LongSeal (254 questions): A needle-in-a-haystack variant where each question pairs with a large set of retrieved documents, only one of which contains or implies the correct answer, buried among irrelevant or misleading content.
Who holds the all-time record at the Grammys for the most wins in the album of the year category?
For Seal-0, we provide the agent with web browsing and scraping tools, then evaluate whether it successfully identifies positive URLs as supporting evidence. For LongSeal, we chunk the provided documents into 512-token chunks to create a fixed corpus, constraining search to this set.
We note, however, some dataset labeling issues which can obscure agent performance. For instance, some LongSeal distractors actually contain correct information, and some URLs containing supporting information are not accounted for, leading to misleadingly low recall scores despite successful information retrieval.
FRAMES#
FRAMES is a multi-hop retrieval benchmark derived from Wikipedia articles. We give the search agent full access to Wikipedia via Serper, prepending queries with the site:[wikipedia.org] filter, with page contents retrieved via the Wikipedia API.
These tasks come with a set of positive Wikipedia URLs, which we use to evaluate recall. We also ensure that all these positive Wikipedia URLs are accessible via the Wikipedia API, and filter out tasks that do not have a URL set completely covered by the API. We note that Wikipedia is largely memorized by LLMs which sometimes leads models prematurely querying with the answer, rather than engaging in genuine discovery-based search.
Imagine there is a building called Bronte tower whose height in feet is the same number as the dewey decimal classification for the Charlotte Bronte book that was published in 1847. Where would this building rank among tallest buildings in New York City, as of August 2024?
HotpotQA#
HotpotQA is a multi-hop retrieval benchmark, simpler relative to other evaluated benchmarks. We include this to demonstrate that our model, along with frontier models, saturates performance on this task.
Results#
| Model ↕ | BrowseComp+ ↕ | LongSeal ↕ | Seal0 ↕ | FRAMES ↕ | HotpotQA ↕ |
|---|---|---|---|---|---|
| Context-1 (4x) | 0.96 | 0.79 | 0.52 | 0.96 | 0.99 |
| Context-1 (1x) | 0.87 | 0.65 | 0.32 | 0.87 | 0.97 |
| gpt-oss-20b | 0.66 | 0.41 | 0.21 | 0.58 | 0.60 |
| gpt-oss-120b | 0.84 | 0.54 | 0.36 | 0.81 | 0.93 |
| gpt-5.2 | 0.82 | 0.85 | 0.48 | 0.95 | 0.98 |
| gpt-5.2 (200k, no prune) | 0.94 | 0.89 | 0.57 | 0.96 | 0.99 |
| gpt-5.4 | 0.84 | 0.85 | 0.56 | 0.96 | 0.98 |
| sonnet-4.5 | 0.87 | 0.82 | 0.48 | 0.96 | 0.99 |
| sonnet-4.5 (200k, no prune) | 0.86 | 0.88 | 0.66 | 0.96 | 0.99 |
| opus-4.5 | 0.87 | 0.81 | 0.62 | 0.97 | 0.99 |
| opus-4.5 (200k, no prune) | 0.92 | 0.88 | 0.72 | 0.97 | 0.99 |
| sonnet-4.6 | 0.83 | 0.75 | 0.47 | 0.96 | 0.98 |
| opus-4.6 | 0.91 | 0.83 | 0.53 | 0.97 | 0.99 |
| gemini-3.1-pro | 0.94 | 0.74 | 0.49 | 0.92 | 0.99 |
| kimi-k2.5 | 0.87 | 0.73 | 0.40 | 0.92 | 0.99 |
We see similar trends of Context-1 having comparable performance to frontier models in these public benchmarks.
Humanity’s Last Exam (HLE)#
Humanity’s last exam (HLE) contains extremely challenging questions across dozens of subject areas, designed by academics and domain experts as a comprehensive measure of broad academic capabilities. From the full dataset, we filter for text-only questions across Humanities/Social Science, Biology/Medicine, Chemistry, and Other domains to isolate search-specific skills (excluding questions requiring multi-modal reasoning or computation).
Which condition of Arrhenius's sixth impossibility theorem do critical-level views violate?
Answer Choices: A. Egalitarian Dominance B. General Non-Extreme Priority C. Non-Elitism D. Weak Non-Sadism E. Weak Quality Addition
Since HLE provides only ground truth answers without positive URLs, we evaluate search effectiveness by comparing two conditions:
- Baseline: the generator model (Opus-4.6 with 5000-token thinking budget) answers directly without search
- With Search: a search agent retrieves supporting documents, which are then provided to the same generator model alongside the question
We compare relative performance gains across different search agent models.
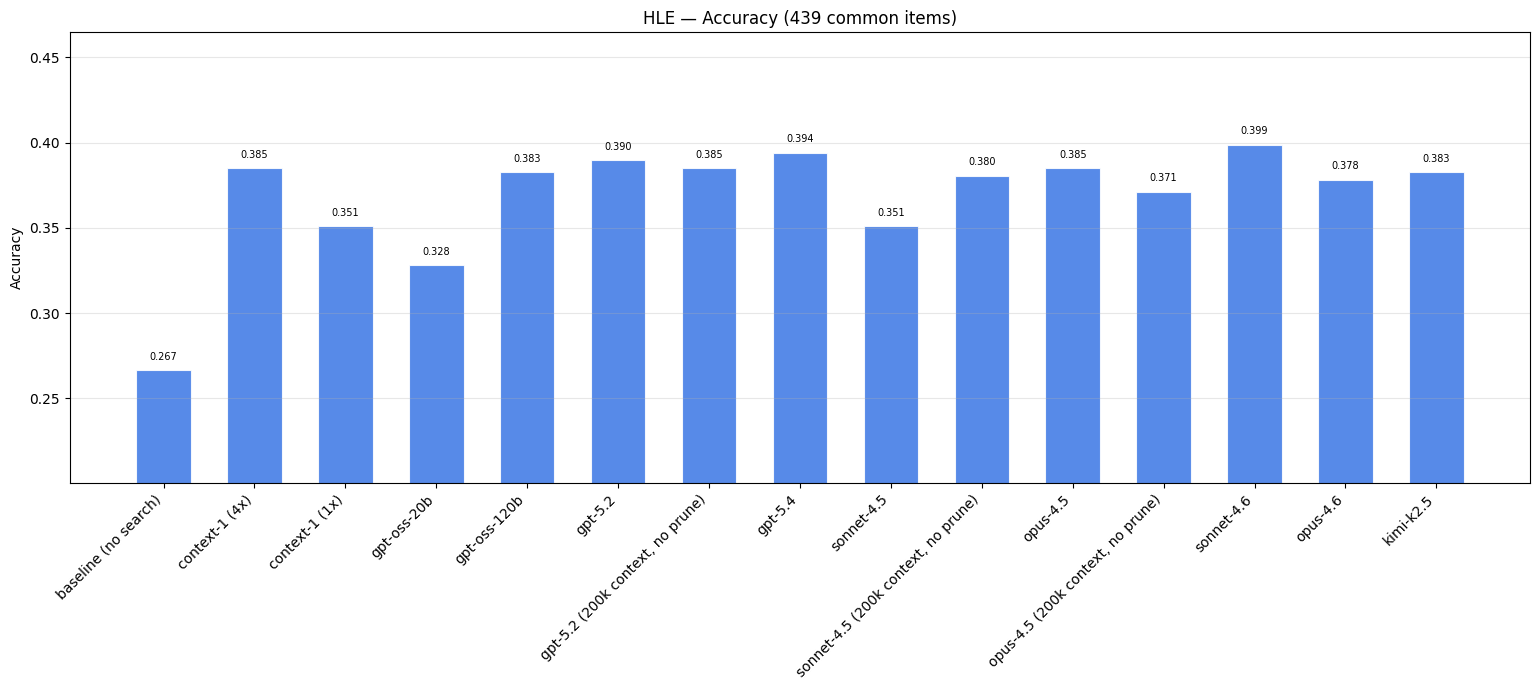
Relative to the baseline of no search, adding a search subagent to the baseline Opus-4.6 improves answer accuracy significantly. The variation in performance gains across subagent models demonstrate the variation in output document quality. However, this variation is not as significant compared to the other benchmarks given the difficulty of the task.
With this benchmark, it’s interesting to notice that removing the token budget constraint does not have a consistent effect across all models. Only sonnet-4.5 saw performance gains with a relaxed token budget, whereas the outputs of gpt-5.2 and opus-4.5 were slightly negatively impacted.
Future Directions#
Task Diversity#
A key limitation of this work is our narrow focus on needle-in-a-haystack style questions: multi-constraint queries designed to locate a single specific answer. While effective for isolating planning and evaluation skills, these tasks are often unrealistic. Real search is typically more abstract; the user does not specify every criterion needed to verify the final result, and part of the task is inferring intent and predicting what information would actually be useful. Additionally, all of our tasks are depth-oriented: the agent must find one piece of information satisfying many criteria. We do not currently cover breadth queries, where the goal is to find all information satisfying a specific criterion, such as "find every SEC filing that mentions supply chain disruption in Q4 2024." Breadth search introduces fundamentally different challenges around completeness, deduplication, and knowing when to stop.
Before pursuing further improvements to the agent itself, the most impactful next step is developing more representative task distributions. This includes a taxonomy of query types (depth vs. breadth, factual vs. exploratory, single-answer vs. aggregation), abstention tests where the correct behavior is to recognize that no satisfying answer exists, and tasks that require the agent to interpret ambiguous or underspecified requests.
Tool Use and Search Infrastructure#
Context-1's current tool set (search, grep, read, and prune) is deliberately minimal. Several extensions could meaningfully expand the agent's capabilities.
Code generation for search. Many real-world corpora contain structured or semi-structured data such as tables, spreadsheets, and JSON, where keyword and vector search are poor fits. Allowing the agent to generate and execute code (SQL queries, pandas operations, regex pipelines) would open up search over structured data that current tools cannot effectively handle.
Schema and metadata discovery. Real corpora come with metadata: timestamps, authors, document types, categorical labels. The agent currently has no mechanism to discover or leverage this structure. Exposing metadata schemas and allowing the agent to construct filtered queries would improve both precision and efficiency, particularly in domains like finance and legal where metadata is information-dense.
Learned reranking. Currently, the reranker is a fixed component in the tool pipeline. An alternative is to let the agent write or parameterize the reranker query itself, effectively controlling how retrieved results are scored and ordered. This could allow task-specific reranking strategies without retraining the reranker.
Orchestrator integration. Context-1 operates as a standalone subagent that returns a static document set. A tighter integration with an orchestrator model, where the generator can steer retrieval in real time by requesting specific follow-ups or clarifications based on partial results, could close the gap between what is retrieved and what is actually needed to answer the question.
Context Management#
Our current approach to context management, hard token budgets with explicit pruning, is effective but rigid. Several directions could make context management more adaptive.
Scratchpad and selective retention. Rather than forcing a binary keep-or-discard decision on each chunk, the agent could maintain a scratchpad: a compressed working memory where key facts, partial conclusions, and cross-references are recorded as search progresses. This would allow the agent to prune the raw text of a document while retaining its informational content in a structured form. An opt-in model, where chunks must be explicitly promoted to the output set rather than included by default, may also produce better precision.
Summarization. We deliberately avoided lossy compression in this work, opting for document-level retention to preserve evidence fidelity. However, hybrid approaches that combine selective retention of high-value passages with targeted summarization or span selection of supporting passages could offer a better tradeoff, particularly for very long search trajectories where the raw evidence volume exceeds any practical budget.
Training#
Late interaction and joint retrieval training. The embedding model, reranker, and search agent are currently trained independently: the agent learns to write queries against a fixed retrieval stack. Context-1's pipeline reflects the standard two-stage pattern: a fast first stage (hybrid BM25 + dense retrieval) trades expressiveness for speed, then a cross-encoder reranker recovers precision at higher cost per candidate. Late interaction architectures like ColBERT occupy a middle ground, preserving per-token representations for both queries and documents and computing relevance via token-level MaxSim rather than compressing into a single vector. This retains much of the expressiveness of a cross-encoder while remaining efficient enough to score over a larger candidate set than reranking typically permits. Jointly training a late interaction model alongside the search policy could let the retrieval stack co-adapt: the embedding learns to produce token representations that are most discriminative for the queries the agent actually generates, while the agent learns to write queries that exploit the retrieval model's token-level scoring.
Self-play. Our current training relies on synthetically generated tasks with fixed ground-truth labels. An alternative is self-play, where one agent generates questions and hides evidence while another searches for it, creating an adversarial curriculum that naturally scales in difficulty as both agents improve.
Ingest-time enrichment. Rather than relying solely on runtime search, offline compute at ingest time (entity extraction, relationship mapping, summary generation) could provide the agent with a richer substrate to search over. This trades offline compute for runtime efficiency, a tradeoff that becomes increasingly favorable as models get faster and the cost of inference continues to decrease.
Conclusion#
We presented Context-1, a 20B parameter agentic search model that reaches the Pareto frontier of retrieval performance with respect to cost and latency. On our generated benchmarks, Context-1 matches or exceeds models that are orders of magnitude larger — and when run in a 4x parallel configuration, it does so while remaining cheaper than a single call to those models. These gains hold across public benchmarks as well: on BrowseComp-Plus, SealQA, FRAMES, and HLE, Context-1 delivers retrieval quality comparable to frontier LLMs at a fraction of the compute.
Three techniques underpin these results. First, a staged training curriculum that shifts the reward from broad recall toward selective precision, teaching the agent to explore widely before narrowing. Second, a self-editing context mechanism that allows the agent to prune irrelevant passages mid-search, sustaining effective retrieval over long horizons within a bounded context window. Third, a scalable synthetic task generation pipeline with extraction-based verification, achieving over 80% alignment with human judgments across all four domains while minimizing the need for manual annotation.
Notably, Context-1 generalizes beyond its training distribution. Despite being trained only on web, legal, and finance tasks, it shows substantial improvements on the held-out email domain and on public benchmarks with different task formats, suggesting that the core skills of query decomposition, iterative refinement, and selective retention transfer across domains.
We release Context-1 as an open weights model along with the full data generation pipeline to support reproducibility and future research. We believe that purpose-trained search subagents represent a practical path toward making agentic search both more capable and more accessible — enabling retrieval quality previously reserved for the largest models at a cost and latency suitable for production deployment.
Acknowledgements#
We are grateful to Chris Manning for early discussions that helped shape the direction of this research. We thank Omar Khattab, Daniel Hunter, Jason Liu, Alex Zhang, and John Schulman for reviewing drafts of this work. We thank Thinking Machines Lab for Tinker, which was used to train Context-1, and for their assistance throughout the training process. We also thank Richard Gong and the Modal team for their support on inference infrastructure.
Appendix#
Task Generation#
Web#
We adapt the explorer agent from WebExplorer, in which an agent is given a seed entity and search tools, then explores the web until it collects enough information to create a challenging question.
Our implementation introduces several modifications:
- Combined explore/evolve loop - WebExplorer separates exploration and question evolution into distinct stages. We find that with few-shot examples of ideal queries and instructions for obfuscation, a single agent loop generates challenging tasks without the extra step.
- Distractor mining - for each task, a separate agent loop collects distractors: webpages that satisfy some criteria but point to a different answer.
- Multi-hop extensions - we bridge answers from existing tasks to new tasks, chaining together dependent questions. This allows us to control task difficulty by varying the number of hops required to reach the final answer.
- Verification - we verify that supporting documents actually support the answer and that distractors are genuine distractors.
Gather supporting documents & generate task
Given a seed topic sampled from random Wikipedia titles, we provide the agent with web search and scraping tools to explore and collect documents containing unique facts related to that topic. We use Serper for web search and Jina AI’s Reader for scraping. To ensure diversity in the types of facts gathered, we also provide a "truth topic" constraint (i.e. the truth must be in category ‘person’); without this, collected facts tended to cluster around patterns in our few-shot examples. We use 17 truth topics.
Using the collected documents, the agent generates clues (obfuscated references to facts), a question combining these clues, and the corresponding answer.
Input: truth_topic: "date" seed_topic: "1878 in Belgium"
Output: clues: "A sacred structure in a western European capital was designed in a style combining two ancient architectural traditions, selected through a competitive process initiated in the late 1860s. The community for whom this building was constructed gained official state recognition during the early 1830s, shortly after their nation achieved independence. Construction of this edifice was completed during the same year a Belgian ocean liner was launched from an English shipyard on the eve of winter solstice."
question: "On what date was this building formally inaugurated?"
truth: "September 20, 1878"
supporting_items: "https://jguideeurope.org/en/region/belgium/brussels/": "Grande Synagogue de…"
Verify task
We verify through extraction and deterministic checking via code tests. For each supporting document, we prompt an LLM to extract: document_quotes, clue_quotes, and contains_truth. We normalize quotes and source text, then confirm the quotes actually appear in the document.
document_quotes: "Brussels, the capital of the European institutions", "The synagogue is in the Romanesque-Byzantine style", "Following Belgium's independence in 1830 and the 1831 Constitution guaranteeing freedom of worship", "The Regency Synagogue was inaugurated on 20 September 1878"
clue_quote: "sacred structure in a western European capital", "style combining two ancient architectural traditions", "gained official state recognition during the early 1830s", "shortly after their nation achieved independence"
contains_truth = True
Simply asking the model whether a positive document is “relevant” is not reliable, and human labeling is costly since it requires reading each document thoroughly. Our extraction approach reduces human verification to checking whether document_quote supports clue_quote. If any document lacks matching quotes, or if no document contains the truth, we filter out the task.
Across 256 manually verified tasks, we get 84.40% alignment accuracy.
Collect & verify distractors
We collect 10 distractors for each task. A distractor is a document containing information similar to the clues but pointing to a different answer.
Given the clues, question, and answer, an agent searches for and collects candidate distractors. We then verify that distractors do not inadvertently contain the correct answer: given a document and the answer, we extract any occurrence of the answer in any form. If the answer appears, we filter out that distractor. Across 256 tasks, we achieve 84% alignment with distractor filtering.
"The story of the Great Synagogue of Rome
The Great Synagogue of Rome is one of the most impressive Italian synagogues built after the Emancipation in 1870 for Roman Jews…”
Chaining
Once a task is complete, we optionally add chaining: taking the answer of an existing question and bridging it to a new task with a new final answer.
clues: "A conflict that began in a southwestern territory during that same year inspired a late twentieth-century ensemble action picture featuring multiple performers associated with a popular generational acting cohort. This production achieved the top position at domestic theaters during its initial release. The soundtrack departed from traditional genre conventions, employing contemporary electronic instrumentation instead of classical orchestral arrangements."
question: "What is the title of this film?"
truth: "Young Guns”
This allows us to control the amount of hops of a given task. Here, we essentially repeat steps 1-4 with a slightly modified step specialized for bridging.
Finance#
We use publicly available SEC filings from 2025 to generate tasks from.
Data pre-processing
We sample 1707 random companies and use EdgarTools to parse filings. We filter to companies with information-rich documents, specifically 10-K and 20-F filings, ensuring sufficient material for task generation. We also filter out corrupted documents (detected via binary markers like %PDF- or abnormal character distributions) and chunks that are predominantly tabular (identified by high whitespace fractions and multi-space alignment patterns).
Generate question and answer through exploration
As with web, we give an agent search and document reading tools, but constrain the search space to a single company. We also provide randomization tools, shuffling chunks across a company or within a document, because SEC filings lack the topical overlap found on the web. On the web, it is expected to find something for any query; here, it’s necessary to discover what's available first. Exploration is less query-driven and more about collection.
We use truth topics here as well, though more limited to guarantee we can actually form those question types from SEC filings.
truth_type: "date" company: "Boeing"
clues: "A company concluded a major work stoppage in late 2024 after union members representing approximately one-fifth of the workforce in a northwestern state voted to approve a new agreement. This agreement replaced an older one that had expired in the early fall season of that year. The shareholders of a major supplier approved merger terms in late winter of the following year."
question: "In what month and year does the new collective bargaining agreement expire?"
truth: "September 2028"
We use chunks rather than full documents because an average SEC filing is 31500 tokens across 7264 filings, and usually only one snippet is relevant. If we marked entire documents as positive, retrieved chunks marked as relevant would often miss the actual supporting information.
Verify positive chunks
We run the same extraction process as web, extracting chunk_quote and clue_quote pairs. If any positive chunk lacks matching quotes, we filter the task. We achieve 93% alignment across 100 tasks.
Collect additional positive chunks
Unlike web, where we build the corpus through exploration, here we use a pre-defined corpus: all SEC filings for a given company. This means we don't explicitly mine for distractors, since similar documents are already present.
However, the same information often appears across multiple filings. A revenue figure in an 8-K may also appear in that year's 10-K. To account for this, we run a collection process for each clue, finding all chunks that satisfy it. We find that across 17064 supporting clues, 67.32% of them appear across multiple chunks and documents. We verify these additional positive chunks using the same extraction process.
Chaining
As with web, we chain tasks by taking an existing answer and bridging it with facts from a different company. This explicit bridging step connects companies, then we repeat steps 1-4 to form the new question.
clues: "The month and year that the new collective bargaining agreement expires is the same month and year that Company B's mortgage on 280 Park Avenue reaches its final maturity date. Company B's governing body underwent adjustments in membership during the mid-decade, adding a new independent member with extensive financial sector experience in the early part of the current year. The oversight group currently comprises individuals who were appointed to provide independent judgment on matters related to the organization, with a majority holding no management roles within the entity itself."
question: "How many individuals providing independent oversight are currently serving on the organization's governing body?"
truth: "5"
Legal#
We sample 1500 USPTO patent publications from Jan 1, 2025 to Jan 16, 2026 and their corresponding non-final office actions. Specifically, we focus on 35 U.S.C. §102 and §103 rejections. A §102 rejection argues that a single prior art reference already discloses every element of the claimed invention. A §103 rejection argues that the claim, while not identically disclosed, would have been obvious to someone skilled in the field given one or more prior art references. Both rejection types require examiners to draw explicit connections between the rejected claims and specific passages in prior art, creating the document relationships necessary for multi-hop search tasks.
Data pre-processing
We download patents and their corresponding documents from the official USPTO. For each patent, we extract: claims, specification, abstract, form 892 (the examiner's list of references), and CTNF (examiner’s non-final office action). When documents are only available as PDFs, we extract via DataLab.
Extraction & verification
Office actions lack standardized formatting. For instance, one examiner may reference prior art by inventor name, another by application number, and language varies across examiners. We use Claude Opus-4.5 to extract structured components from each rejection:
- The rejected claim number
- Referenced prior art (normalized to application numbers using form 892)
- The examiner’s reasoning for why the claim was rejected
We verify extraction accuracy through manual labeling, and get 98.3% accuracy across 117 tasks.
Collect prior art & similar patents
Using the application numbers from extraction, we retrieve the full text of referenced prior art patents. For domestic patents after 2001, we pull directly from USPTO. For older or international patents, we use Google Patents via SearchAPI. We extract the abstract, description, and claims from each referenced patent.
For distractors, we collect patents returned as “similar” in the Google Patents search results, which share topical overlap but were not actually cited as prior art.
Task generation
Eask asks the model to find the prior art given an obfuscated description of the rejected claim and the reasoning connecting them. Because examiner rejections argue for similarity rather than stating exact matches, the connection alone may not uniquely identify the prior art. We add distinguishing details from the prior art itself (specific technical features) to ensure a unique ground-truth answer.
Since patent examiners have already established and justified the document connections, we do not run additional verification for task-document pairings; the rejection itself serves as expert-verified relevance.
Task: [Claim]... This claim is rejected based on Prior Art A. Prior Art A describes a system for authenticating tangible items using a decentralized record-keeping approach. The document covers obtaining spectral emission data from a material when subjected to energy exposure, along with additional identifying information. Prior Art A addresses the cryptographic protection requirement through its description of verification proofs using paired asymmetric encryption credentials, where such proofs can be created and validated to confirm the identity of entities and uniquely identify physical items. Find the prior art matching these details.
Email#
Data pre-processing
We use a pre-processed dataset of Epstein emails, then perform further processing. Email threads often appear multiple times with minor variations: an additional reply, a forwarded copy, or slight formatting differences.
We deduplicate in two passes:
- Using normalized Levenshtein distance (removing threads with less than 10% character-level difference)
- Then using semantic similarity via text-embedding-3-small (removing threads with cosine similarity above 0.8). After deduplication, we retain 984 unique email threads.
Task generation
We give an agent search tools to explore the email corpus. The agent begins with a random seed of emails to understand the data landscape: recurring names, locations, topics, and temporal patterns. From these, it identifies opportunities for multi-hop queries that span threads: for instance, connecting a meeting discussed in one thread to travel arrangements in another.
truth_type: "organization"
clues: "An individual who has worked on developing operating systems shared an article from a media outlet about a decentralized digital currency gaining acceptance in the nation's capital, noting a specific percentage gain on their holdings. In another thread, a journalist from this same media outlet reached out to a legal professional about a declaration filed in federal court concerning allegations about a former head of state and time spent on an island. This media outlet also published coverage of a controversial tell-all book about an administration, which was referenced when an assistant mentioned being unable to print an article due to lacking a subscription."
question: "Which media organization published all three pieces?"
truth: "Washington Post"
We verify tasks in two steps. First, we run extraction-based verification as in the web domain, pulling clue and document quotes to confirm alignment. Second, we run a coherence check: given the clues, question, answer, and all supporting items with their content, we verify that the items connect logically and form a coherent path to the final answer. Tasks must pass both steps to be included in the final dataset.
Across 200 tasks, we get 87.5% alignment with human labels.
Adding Enron emails
The Epstein corpus alone is too small for challenging retrieval; with few emails, even naive search finds relevant documents easily. We augment with emails from the Enron corpus, replacing names and dates to match the distribution found in Epstein emails. This serves two purposes: it increases corpus size from 1,366 to 396,510 chunks, and it introduces plausible distractors that share the stylistic patterns of the target emails without containing relevant information.
The name and date replacement ensures the augmented emails blend naturally with the authentic corpus, preventing models from distinguishing real targets from augmentation based on surface features alone.
Prompts#
You are a retrieval subagent in a multi-agent system. Your specific role is to identify and retrieve the most relevant documents from a large corpus to help another agent answer questions. You do NOT answer questions yourself — you only find and retrieve relevant documents.
Here is the query you need to find documents for:
<query>{query}</query>
Available Tools:
SearchTool: Hybrid semantic and keyword searchGrepTool: Text pattern matchingReadDocument: Read specific document snippets that look promising but incompletePruneChunksTool: Remove irrelevant chunks to free up context space
Your Process:
- Break down the query into its key concepts and information needs (list each one explicitly)
- For each key concept, develop a specific search strategy that targets that concept
- Consider what types of documents and evidence would be most helpful for answering this query
- Plan several distinct, non-overlapping search strategies that approach the question from different angles
- Then execute your searches using multiple parallel tool calls
Your Thinking: After each round of searches, consider:
- What do I know? List the key topics, themes, or aspects of the question that your currently retrieved documents address.
- What should I search for next? Systematically consider what search approaches, keywords, or document types you haven't yet tried that might yield valuable information.
- What should I prune? If you were to prune chunks, what would you remove and what new searches would you prioritize?
- Do I have enough information? Given the question's complexity and requirements, do you have sufficient information to help answer it, or are there critical gaps?
Decide if additional searches are needed (ensure they use genuinely different approaches and do not duplicate prior searches). Avoid getting stuck on a single search strategy — if one approach isn't yielding results, prune and try different approaches.
Tactics to Consider:
- When queries fail, try different approaches or keywords
- Avoid duplicate or redundant searches
- Execute multiple tool calls in parallel when possible
- If your token budget is approaching the threshold, prune irrelevant chunks proactively to avoid running out of context
- Focus on gathering as much relevant information as possible; multiple perspectives on the same topic help confirm findings
- Follow explicit textual evidence rather than speculation
Output Format: Present your final results in order from
most relevant to least relevant:
<Document id={document_id}><Justification>Brief explanation (1–3 sentences) of why this document is relevant to the query.</Justification></Document>
Your final output should consist only of the up to N ranked document results in the specified format and should not duplicate or rehash any of the search planning or evaluation work you did in the thinking block.
If you find our work useful, please consider citing us: