Chroma Web Sync
Chroma Sync now supports web pages. Automatically crawl, scrape, chunk and embed web pages directly into Chroma Cloud.
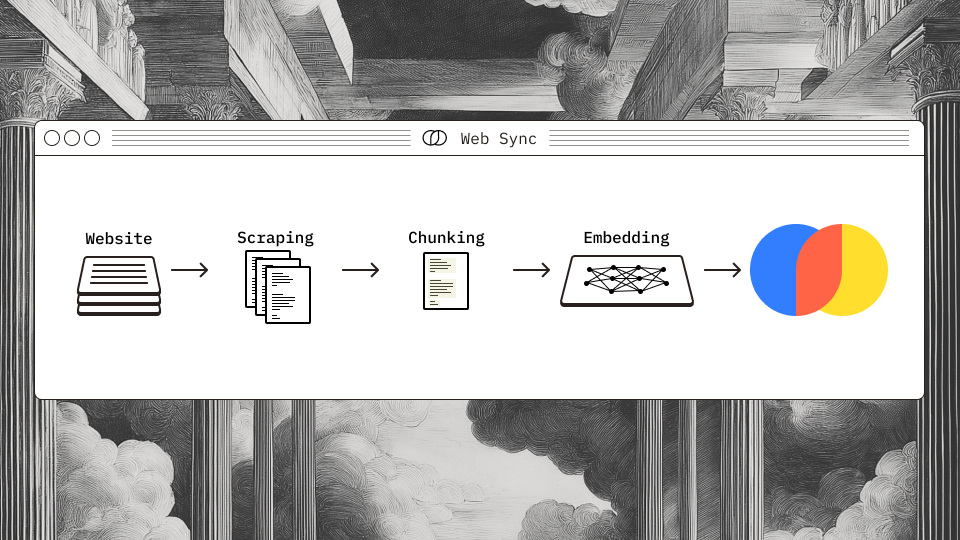
Chroma Web Sync enables entire websites to be ingested into Chroma Cloud by simply supplying a starting URL. No need to manage ingestion pipelines. Chroma Web Sync turns any website into a searchable index in Chroma.
Scraping Challenges#
Scraping websites can be painful. Between DOM changes, rate limits, and half-working pipelines, keeping a web dataset fresh usually means debugging crawlers instead of building features. Chroma’s Web Sync fixes that by letting you automatically crawl, chunk, and embed any website directly into Chroma Cloud. Web pages are first extracted to markdown, then chunked using Tree-sitter.
Use Web Sync to index your product docs, change logs, support pages, blogs, or any other source of information on the web your agents or retrieval systems depend on. Paired with Chroma’s hybrid search capabilities, your agents can get the right context to accomplish your user’s needs.
Hybrid retrieval#
Web Sync collections in Chroma automatically support hybrid search, combining dense vector embeddings and BM25 sparse vectors under one query interface. Dense vectors capture semantic similarity, helping your agents find conceptually related pages even when keywords don’t match, while BM25 preserves traditional keyword precision for exact terms, names, and identifiers.
To learn more about how to work with hybrid retrieval and Web Sync, check out the docs.
You can start using Web Sync in Chroma Cloud today by adding a new Sync source and selecting “Web.” Just point it at any site you want to index and Chroma will handle the crawling, extraction, and embedding automatically.