
Chroma v0.4#
Our biggest release yet#
July 19, 2023
Today we’re announcing the biggest release for Chroma yet - v0.4.
Over the last several weeks, we’ve been hard at work substantially improving Chroma’s internals. While developers will still get the same easy-to-use API, Chroma is now more stable, easier to install and run than ever before. It’s Chroma first true *********production oriented********* release.
This release marks our next step toward a scalable, fully distributed version of Chroma, to give all application developers the power of programmable memory for AI.
Chroma’s Origins#
Chroma was originally built to handle analytical workloads over embeddings. Analytical workloads require OLAP databases for efficiency, and we originally chose ClickHouse and DuckDB as they were the easiest tool to use.
As Chroma made the shift to a general purpose embeddings store for AI applications, we found that these earlier choices created countless issues for our community - including issues with building these dependencies, the operational complexity of managing them, as well as the performance and correctness of the storage layer itself.
Many developers found it cumbersome to reason about the various topologies in which Chroma could be deployed, as well as the resource constraints across its services. They struggled to understand what kinds of machines to use for the server node vs for ClickHouse, and dealt with consistency issues across these disparate datastores. Additionally, Chroma was not thread-safe, and we received many reports of users encountering issues while trying to run it in a multithreaded environment.
Chroma v0.4 addresses all of these issues, fixes dozens of bugs, incorporates critical changes from the community, and lays the foundation for a distributed architecture that can scale past a single node. All while preserving the simplicity of the API you know and love.
The New Release#
The new release addresses the issues created by Chroma’s original architecture, while at the same time simplifying and consolidating it. It also adds a robust, model-based and property-based testing suite that gives developers confidence while making changes to Chroma.
Chroma is now easier to install and run than ever before - we’ve eliminated DuckDB and ClickHouse as system dependencies and unified the document storage by using SQLite across both local and client/server deployments. SQLite delivers great performance for our use case and also provides a robust set of full text search functionality.
This architecture results in less memory usage, simpler infrastructure, and a more robust local storage solution. Additionally, the core vector index now implements a less-naive storage scheme, whereas before it serialized the entire index to disk per-write, it now incrementally updates the on-disk copy. While there is much work ahead to make this system as fast as it can possibly be, this solves many persistence issues users have faced with Chroma.
Chroma is also now safe for multithreaded access when querying, updating, adding or deleting data. We’ve taken care to design a coarse-locking scheme to prevent data corruption, and will work to make this system even faster over time.
Architectural shift
Previously, Chroma used clickhouse as an optional document store, which was the recommended path for deploying Chroma in client/server mode. If you were not using ClickHouse, data was stored in an in-process DuckDB database.
The new version of Chroma is just a single-node in both local and client/server deployments. This node stores documents, metadata and the core vector index. This greatly simplifies deploying Chroma, makes it easier manage, and also makes for an easier to transition from a local version of Chroma to a client/server version.
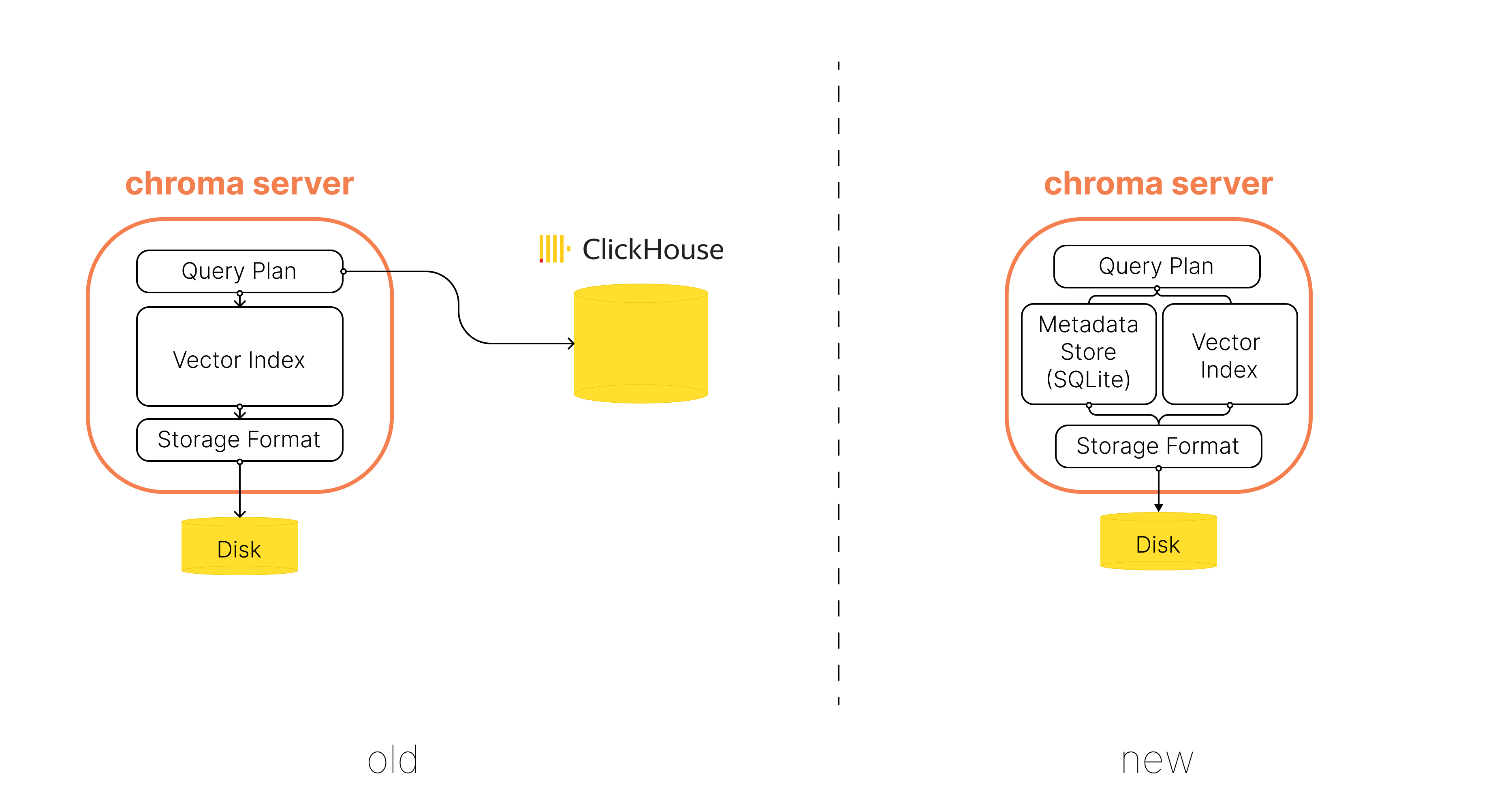
Storage engine
Previously, the vector index was written completely out to disk on every add, update or delete. Now, we adopt a three-tier storage approach - brute force, vector, and vector-on-disk. We first batch vectors in python in a brute force index, periodically, this batch is flushed from python into the c++ vector index. Batching at the python layer helps us save the overhead of calling into c++ from python. The new storage engine keeps the index in memory, but writes-behind dirty values to disk. While simple, this storage scheme is leaps and bounds better than the previous version that existed in Chroma, and we will continue to deliver improvements to it over time.
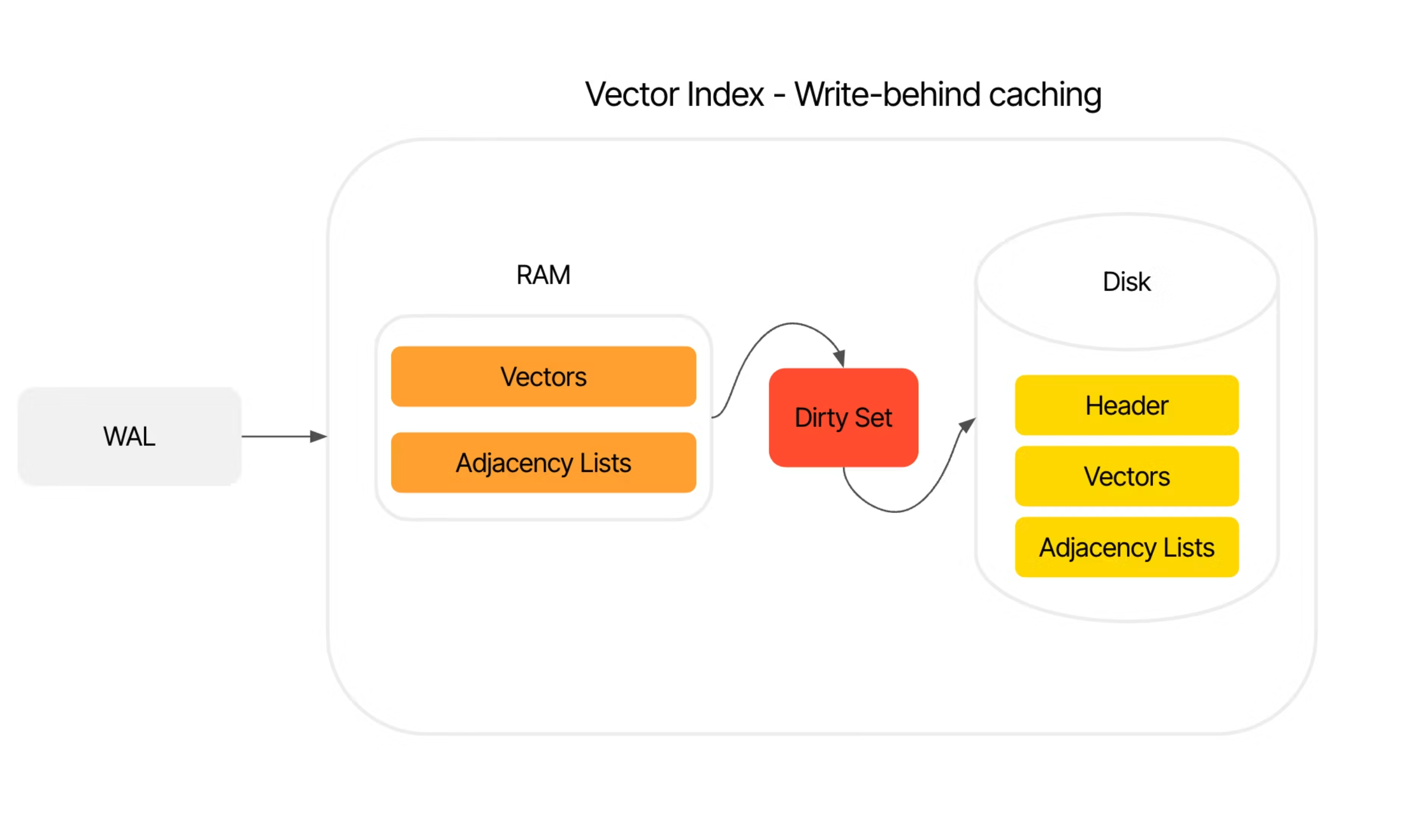
Model based testing
We also added extensive generative, property-based and model-based tests to help us be confident in a refactor of this size, and to have confidence in future changes. We’ll be discussing our testing suite and plans for testing situations like concurrency, in a future post.
Client Creation Shortcuts
We've added the shortcuts chromadb.EphemeralClient, chromadb.PersistentClient and chromadb.HttpClient to make it easier to create clients for common use cases, rather than having to pass in a Settings object to chromadb.Client, which many users found confusing and cumbersome. For users needing more fine grained control, chromadb.Client still exists and can be used as before.
Migration#
Schema and data format changes are a necessary evil of evolving software. We take changes seriously and make them infrequently and only when necessary.
Chroma's commitment is that whenever schemas or data formats change, we will provide a seamless and easy-to-use migration tool to move to the new schema/format.
To use this release, you may need to move your data from older versions of Chroma, and change how you create your API client. We’ve provided a CLI tool for doing so, which you can learn more about here on our migration guide or by joining our discord for help.
What’s Next#
In the near future, we will follow up this major release with improvements to our logging, error handling and metrics hooks, support for checkpointing/snapshotting, a better system for upgrades and recovery as well as a way to estimate resource needs for your data scale.
Additionally, we plan to focus on features that help you make sense of embeddings and work with your data more intelligently, an example of this is the work we have been doing on density-driven relevancy.
Looking further ahead, the next big milestone is moving past single node, to run as a scalable distributed system. Today's release creates the modularity and architectural components necessary to take our next step down that path. We’ll be going into detail about our architecture and choices in future posts (we also discuss it in our monthly town halls on discord, join if you are interested!).
Chroma’s distributed architecture will power Chroma’s cloud service, which will deliver programmable memory for AI application developers through an easy to use, fully scalable service with usage based pricing.
Contributing#
Chroma is open source software, and we highly value contributions from the community. This release represents a step change in Chroma’s architecture, and now is a great time to get started contributing to Chroma. Find us on GitHub, and join our Discord.